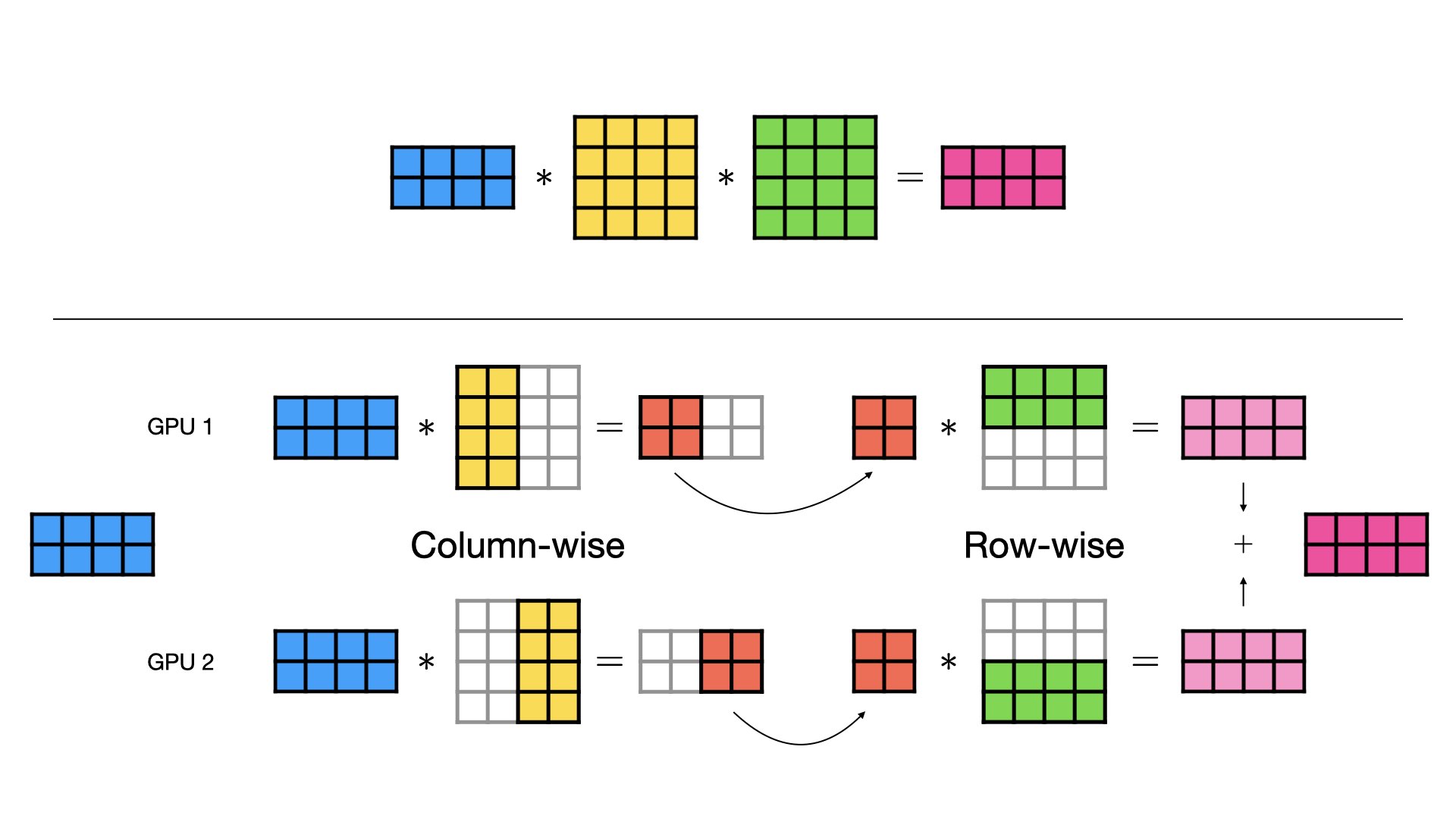
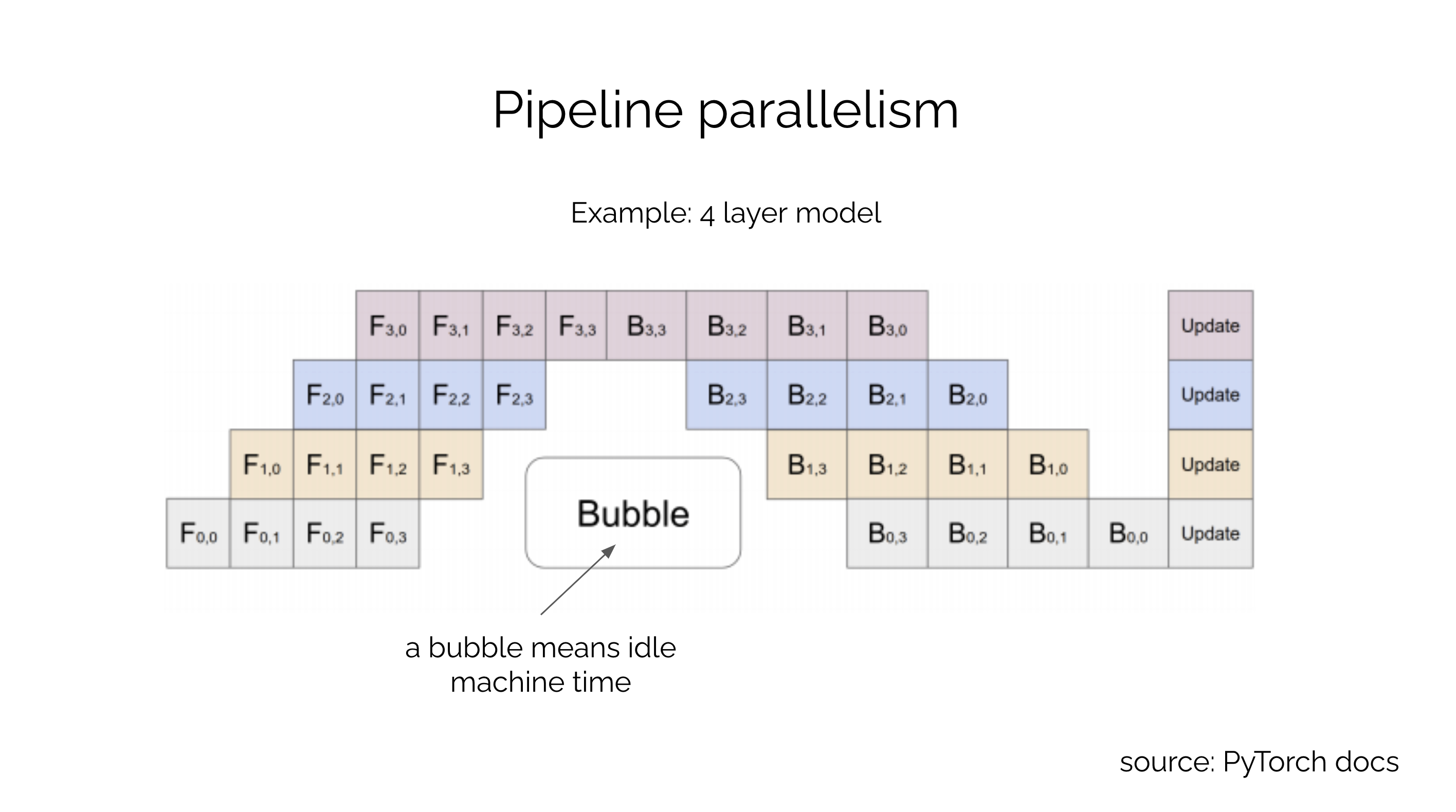
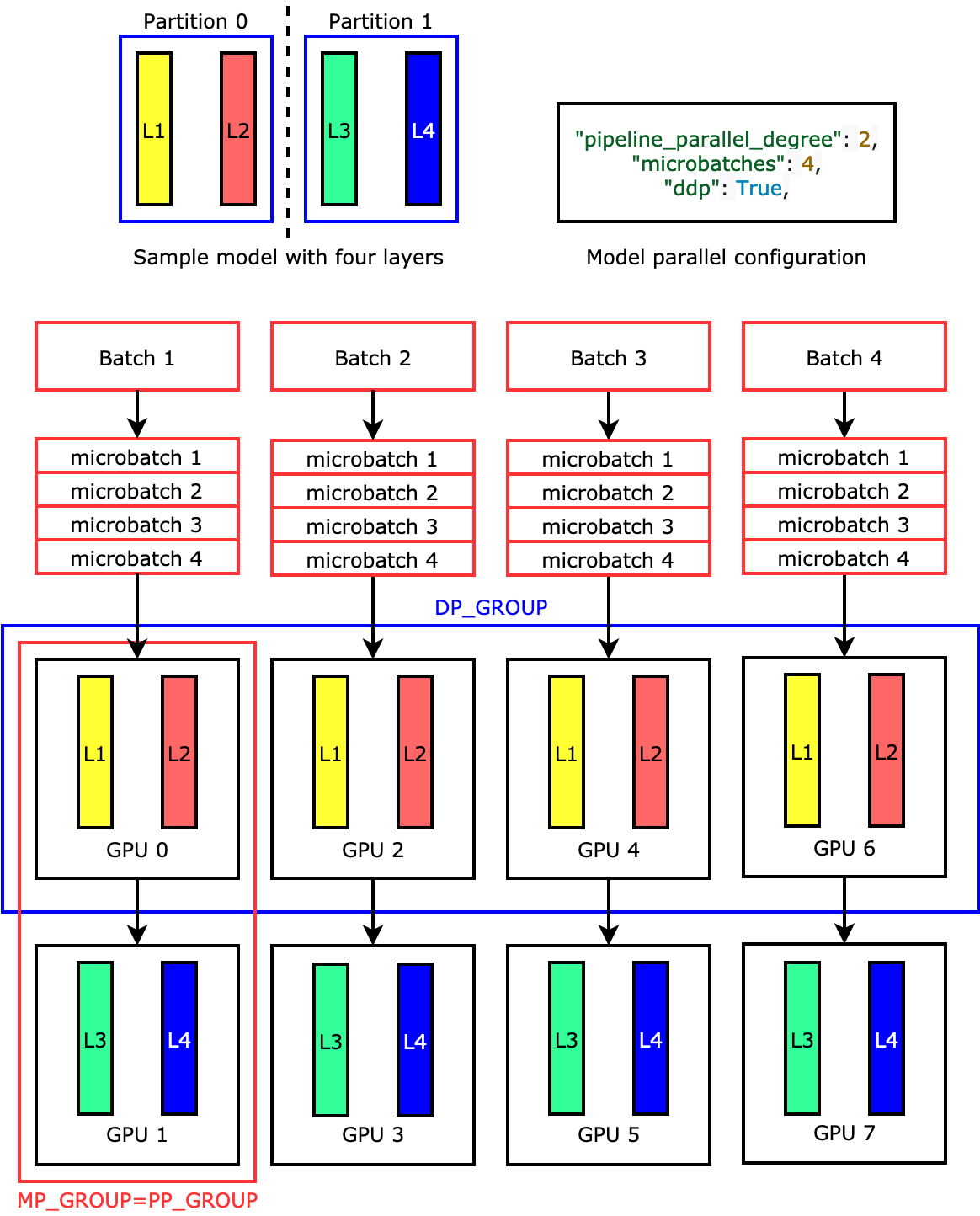
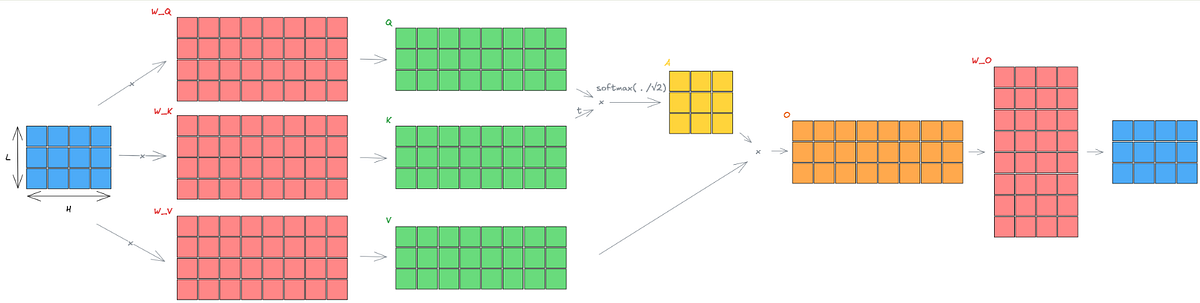
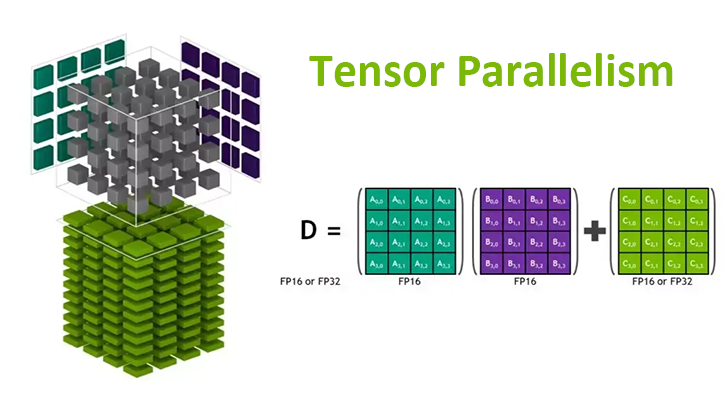
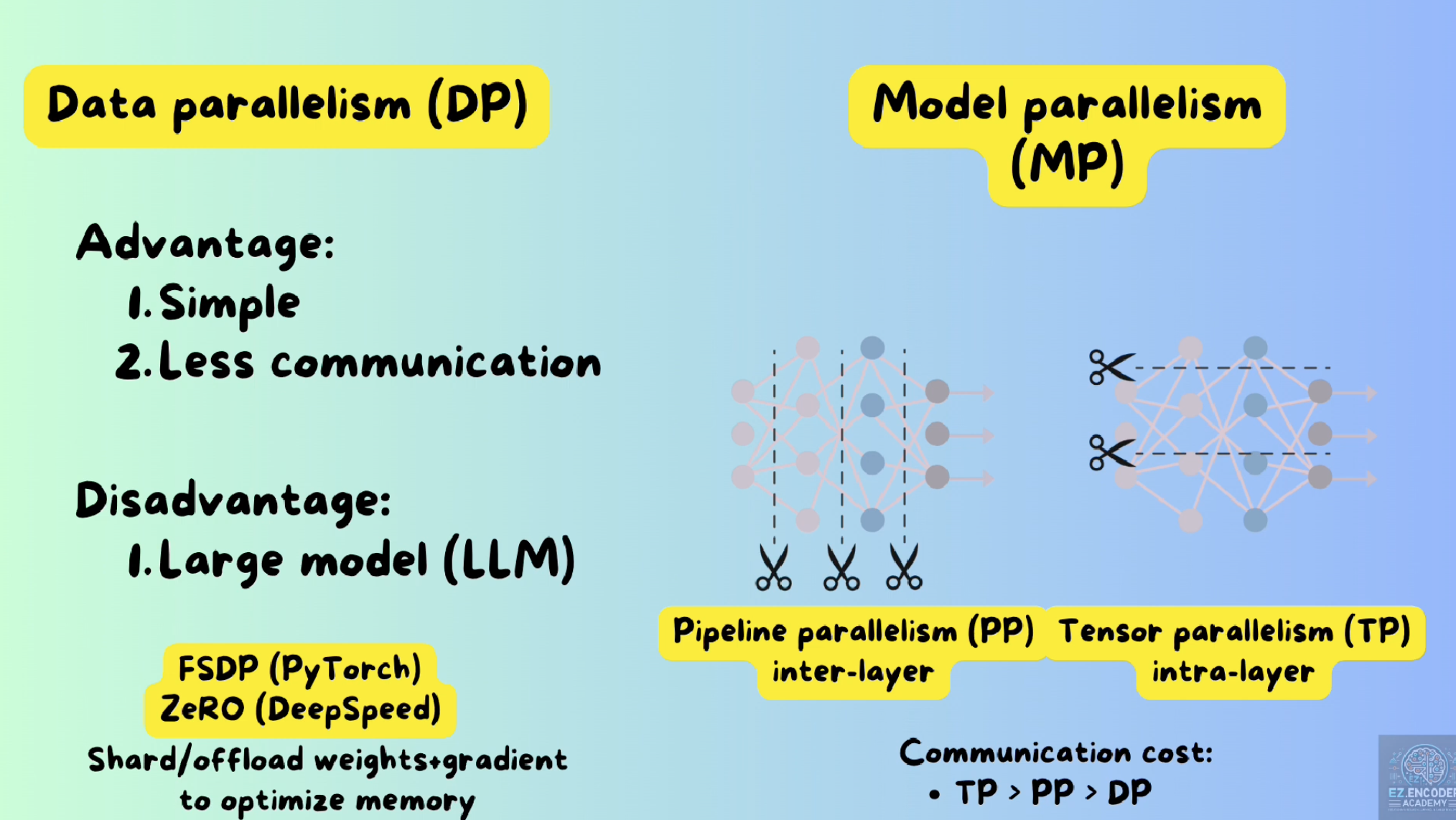
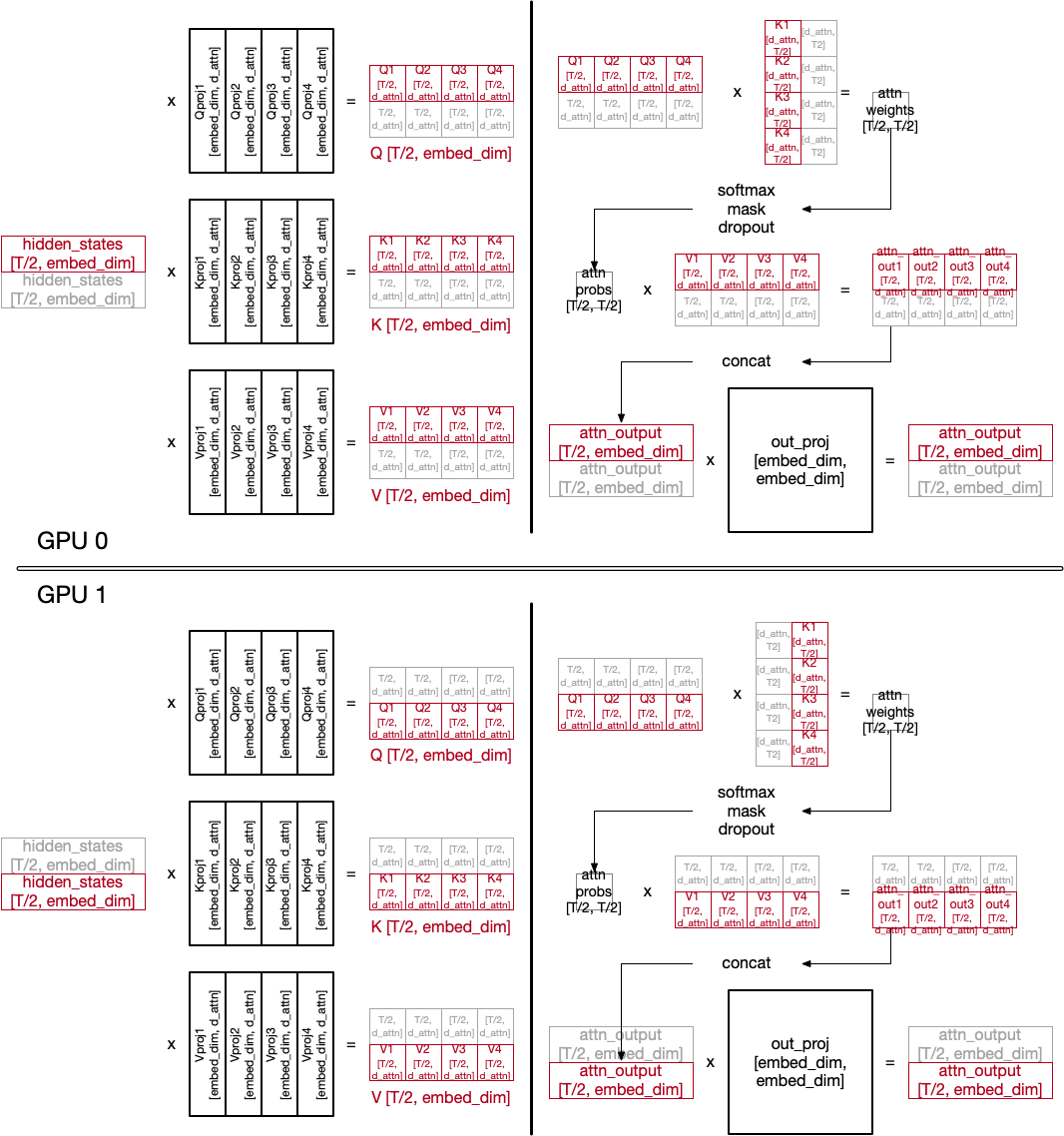
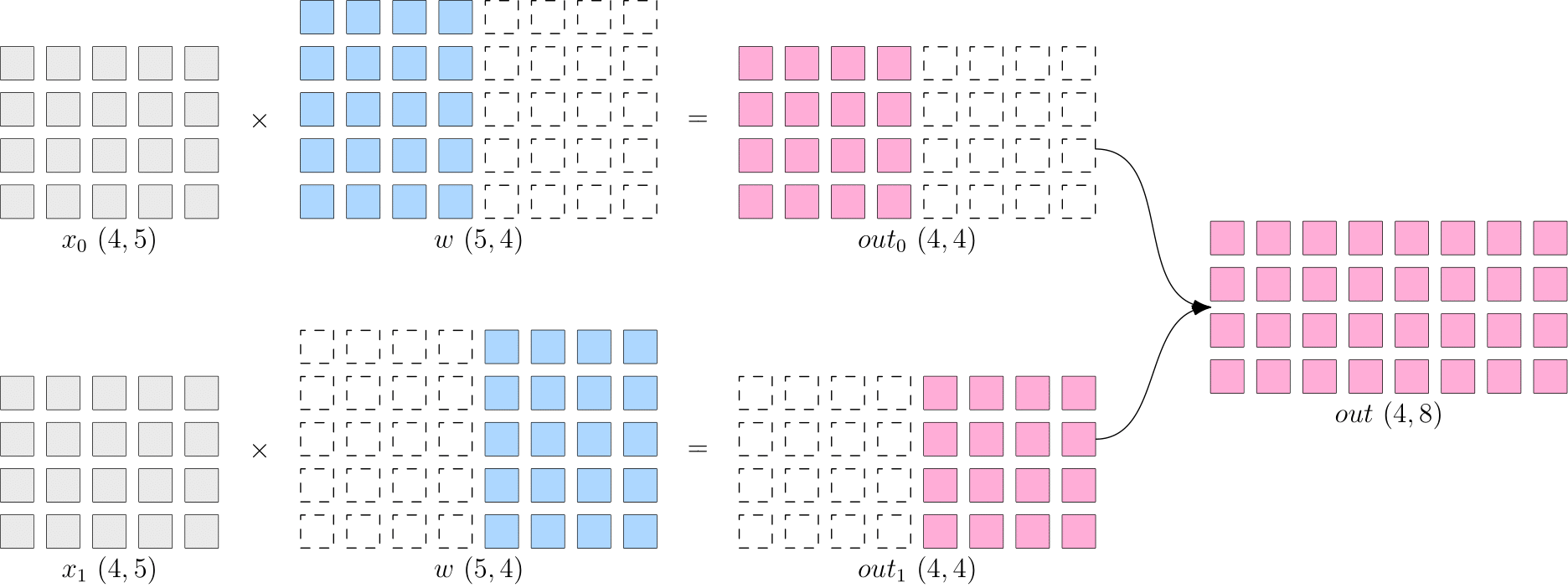
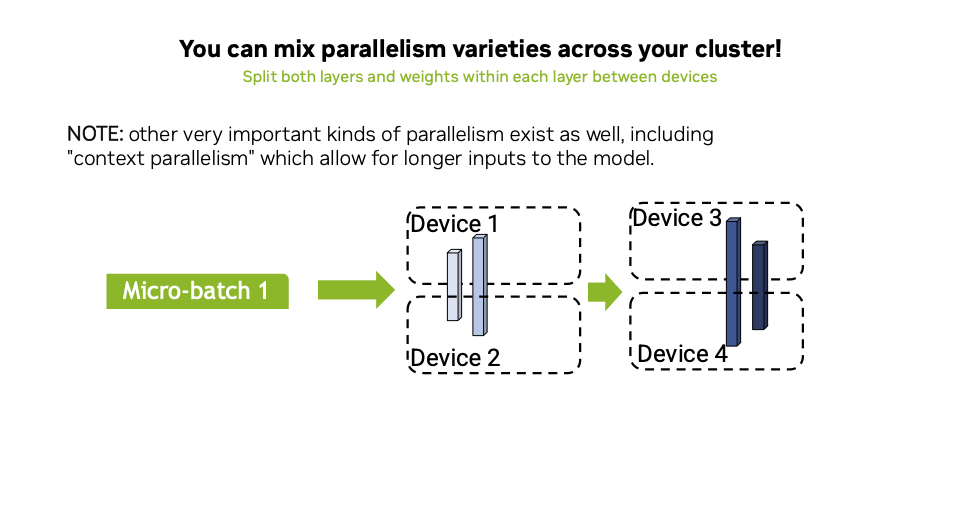
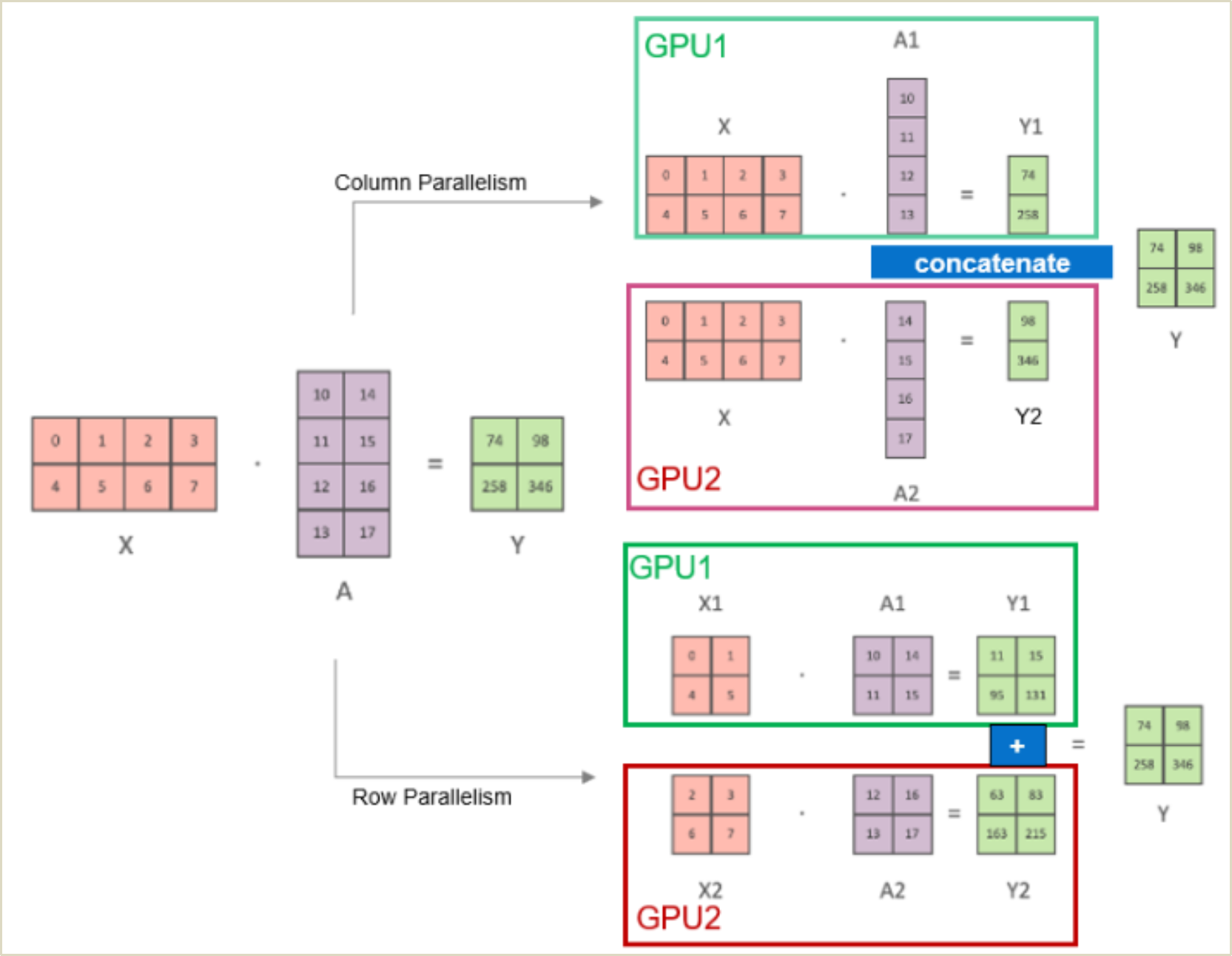
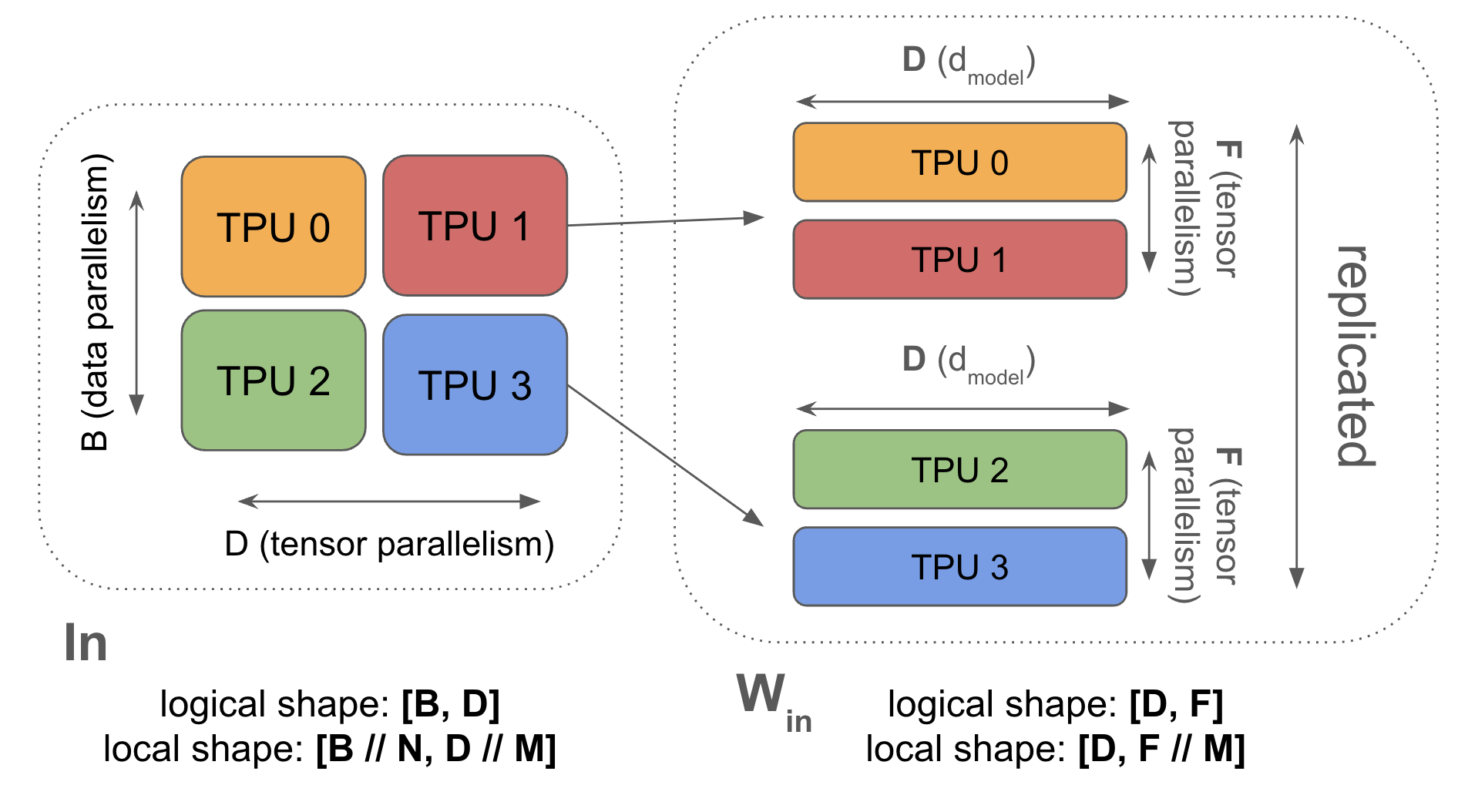
Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
Train Your Large Model on Multiple GPUs with Tensor Parallelism ...
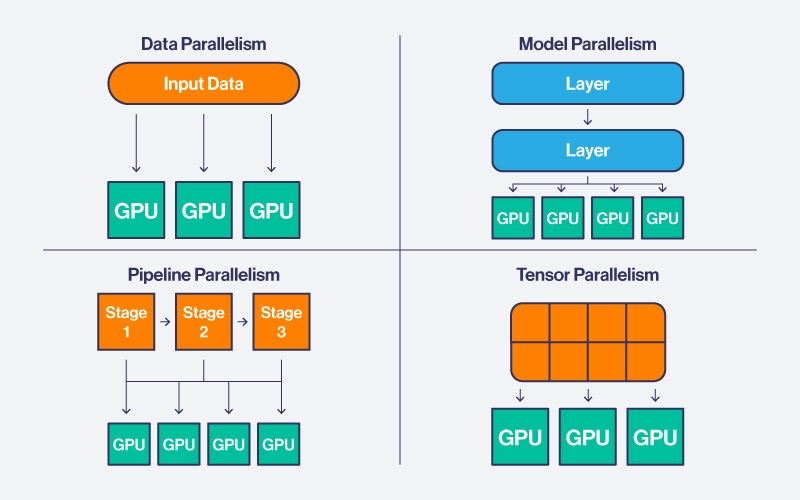
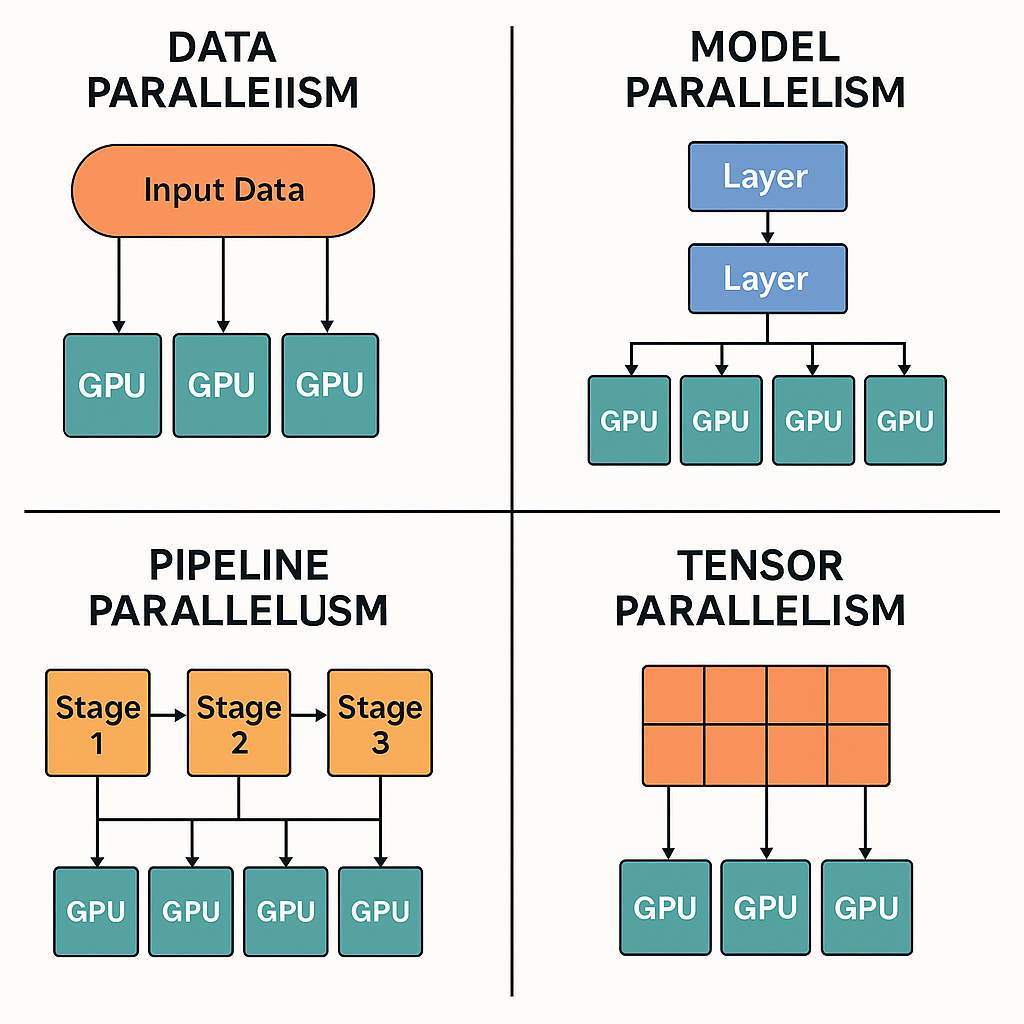
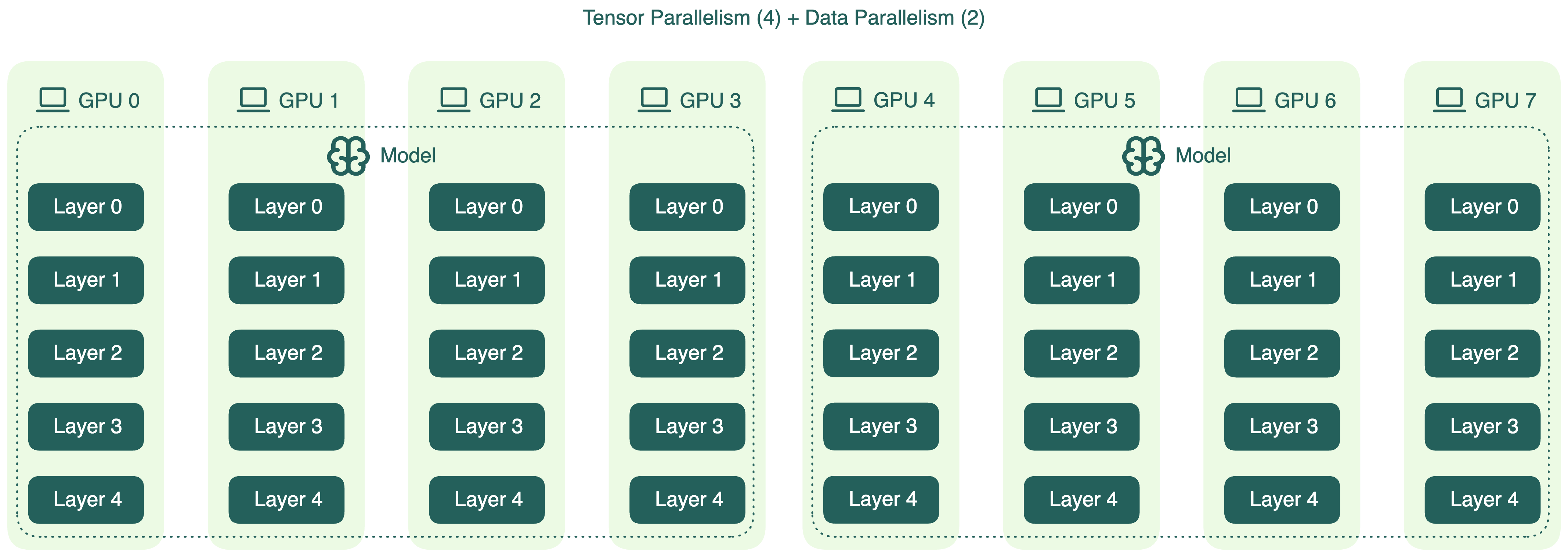
Model Parallelism vs Data Parallelism vs Tensor Parallelism | # ...
Tensor Model Parallelism Tutorial — OSLO documentation
Figure 1 from Automated Tensor Model Parallelism with Overlapped ...
Automated Tensor Model Parallelism with Overlapped Communication for ...
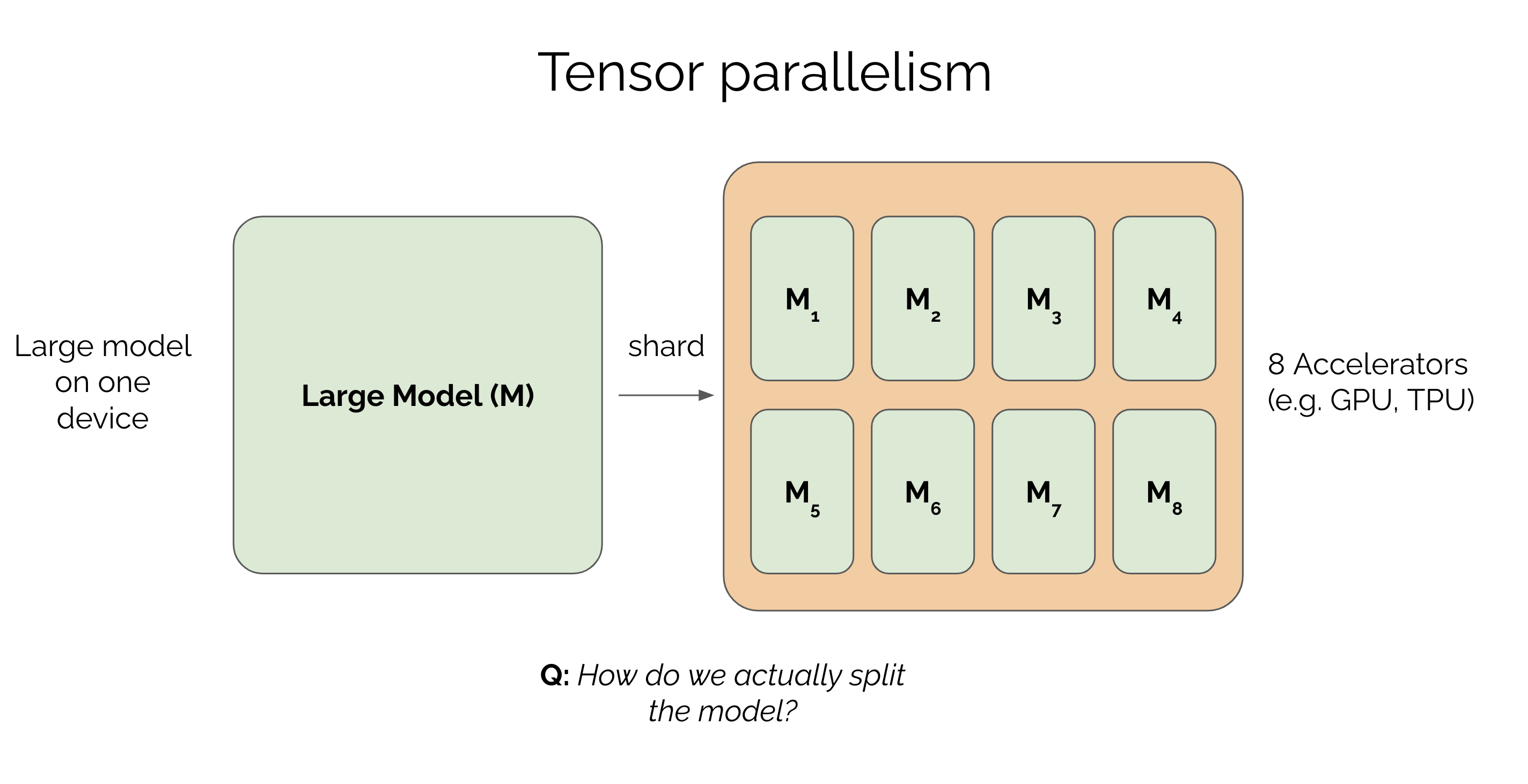
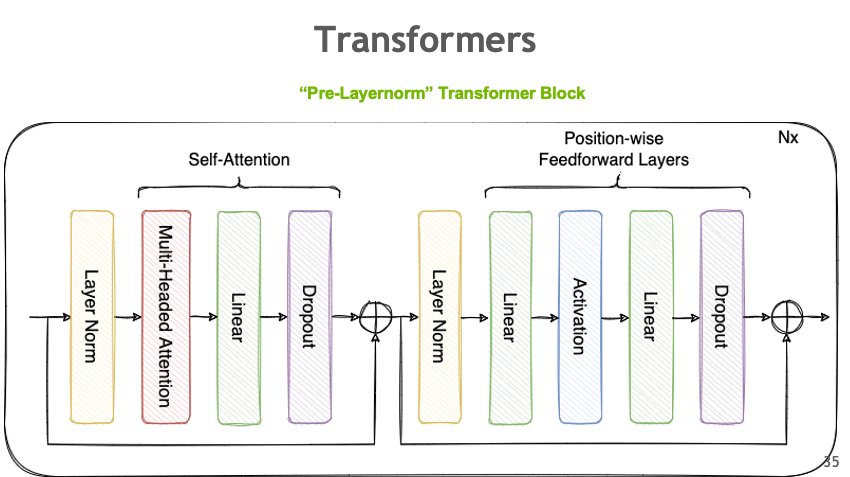
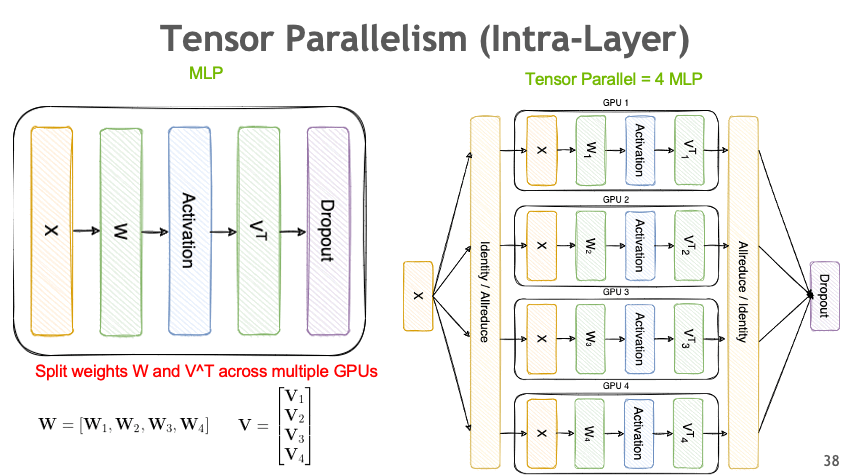
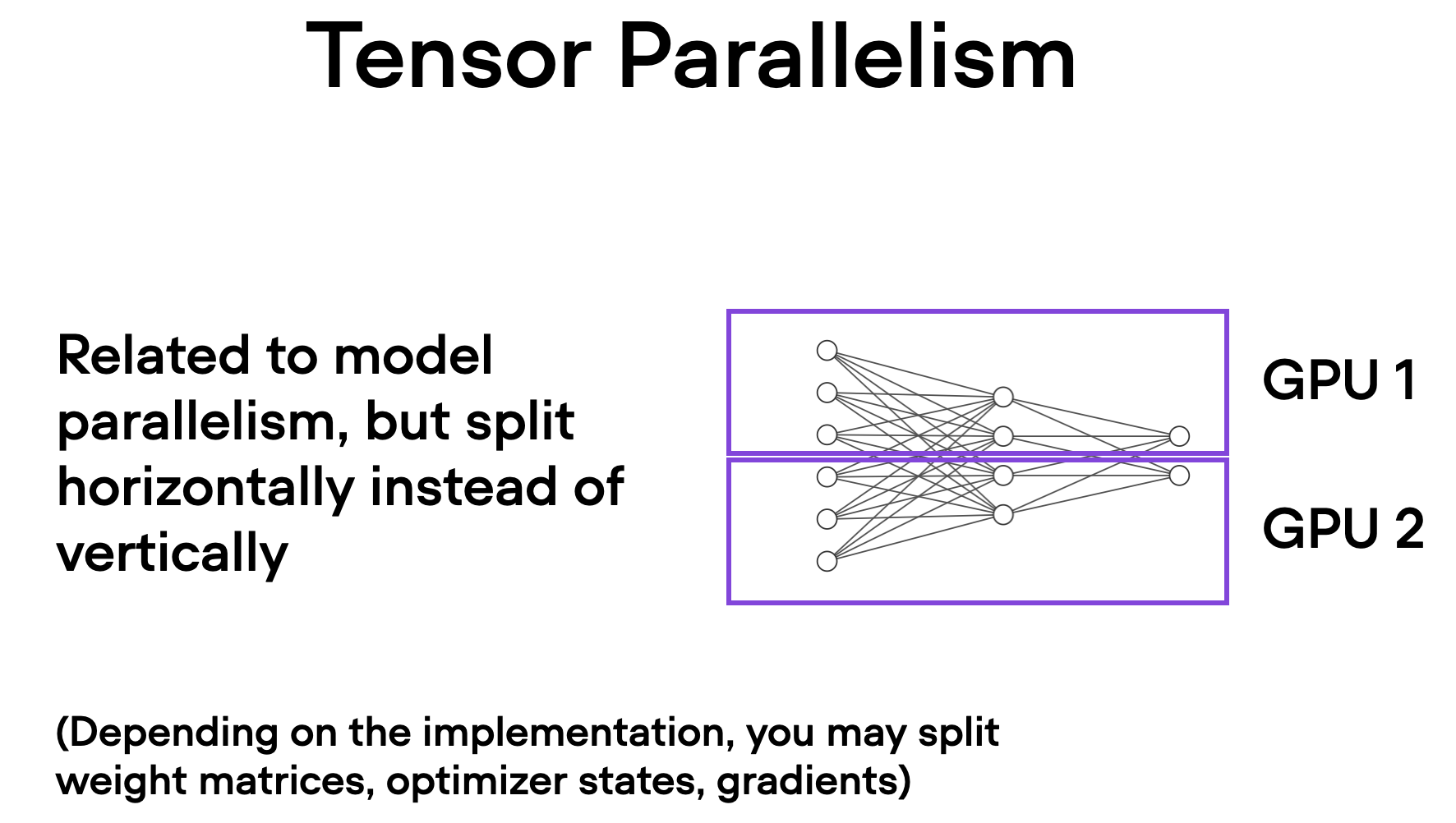
Tensor Parallelism
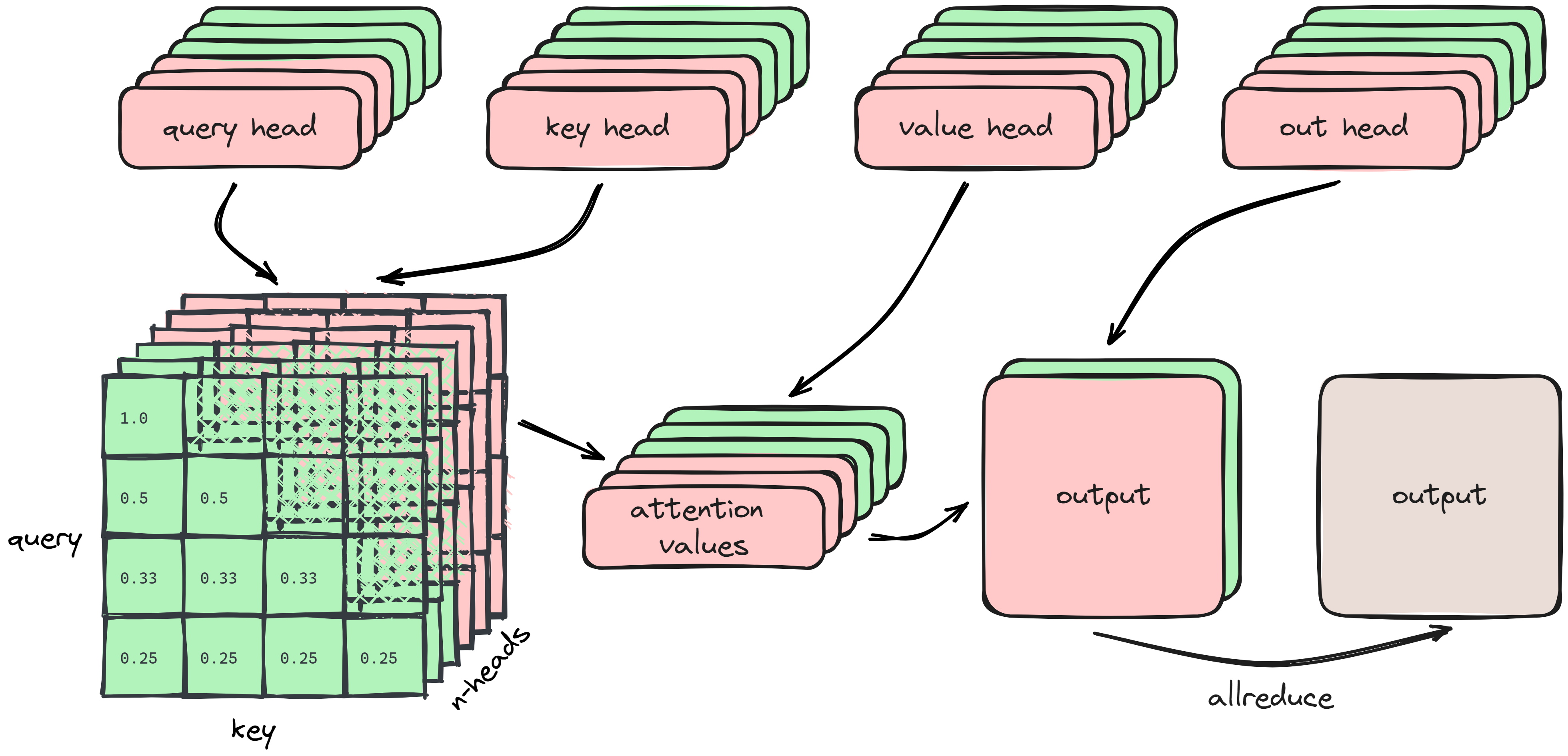
How Tensor Parallelism Works - Amazon SageMaker
Introduction to Model Parallelism - Amazon SageMaker AI
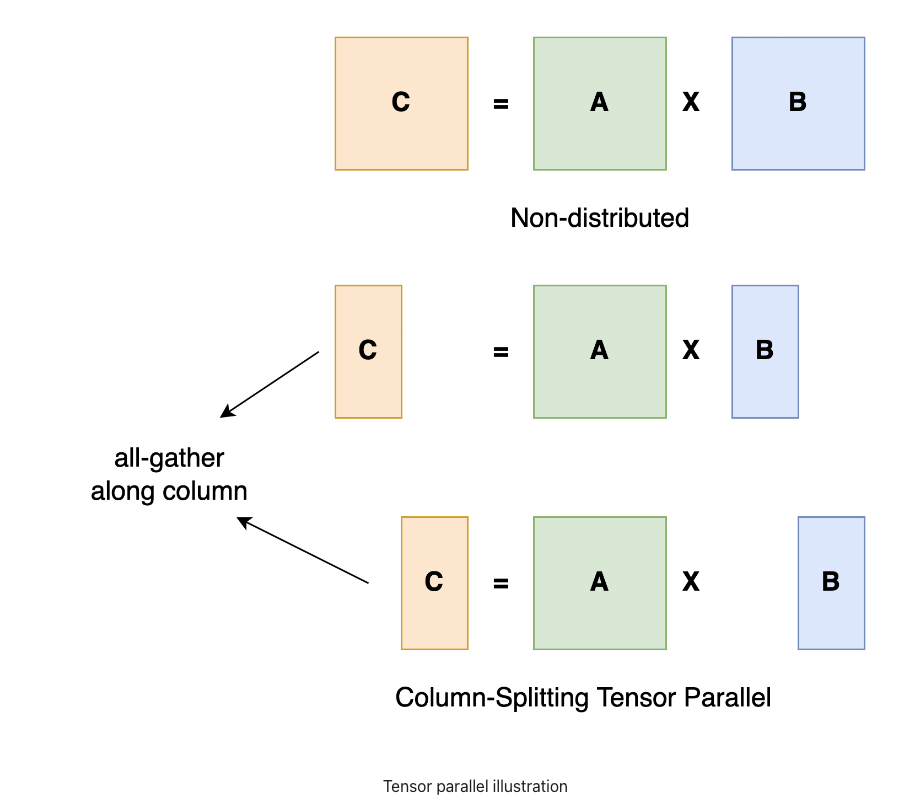
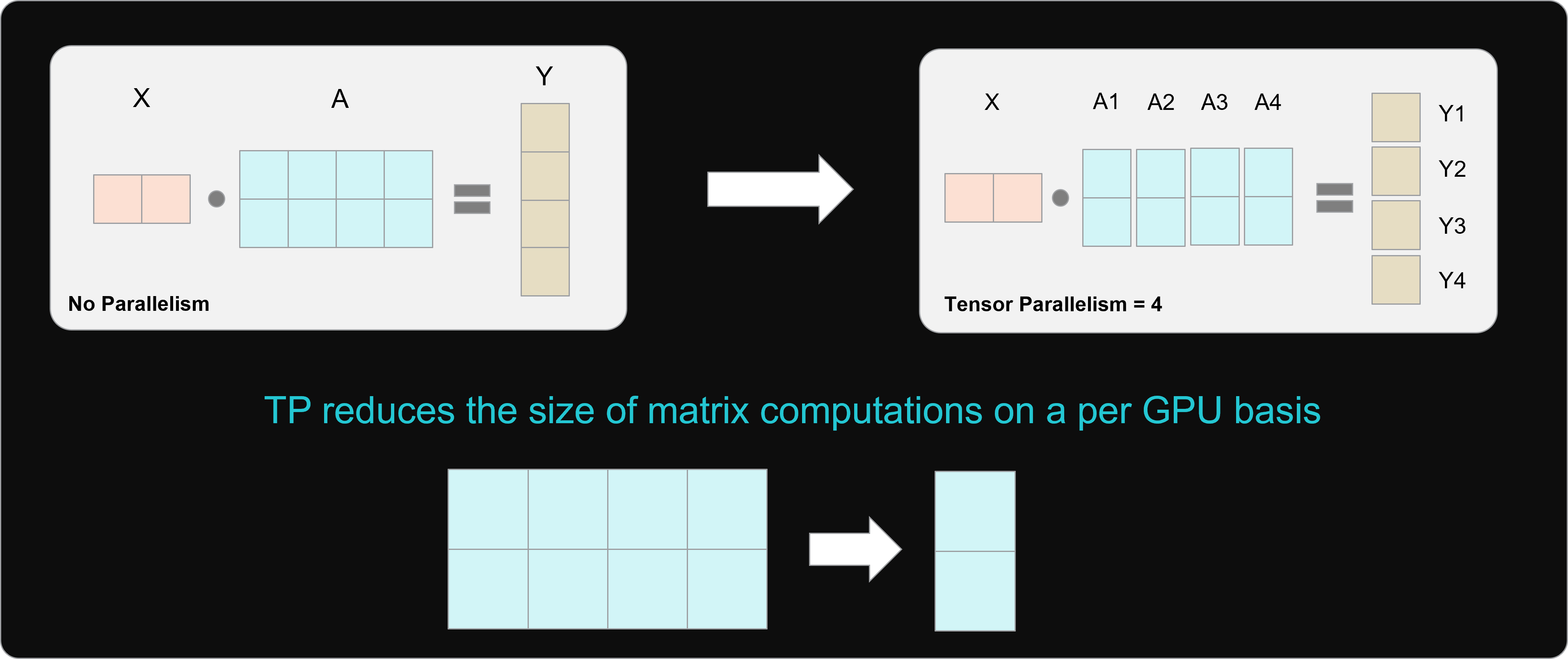
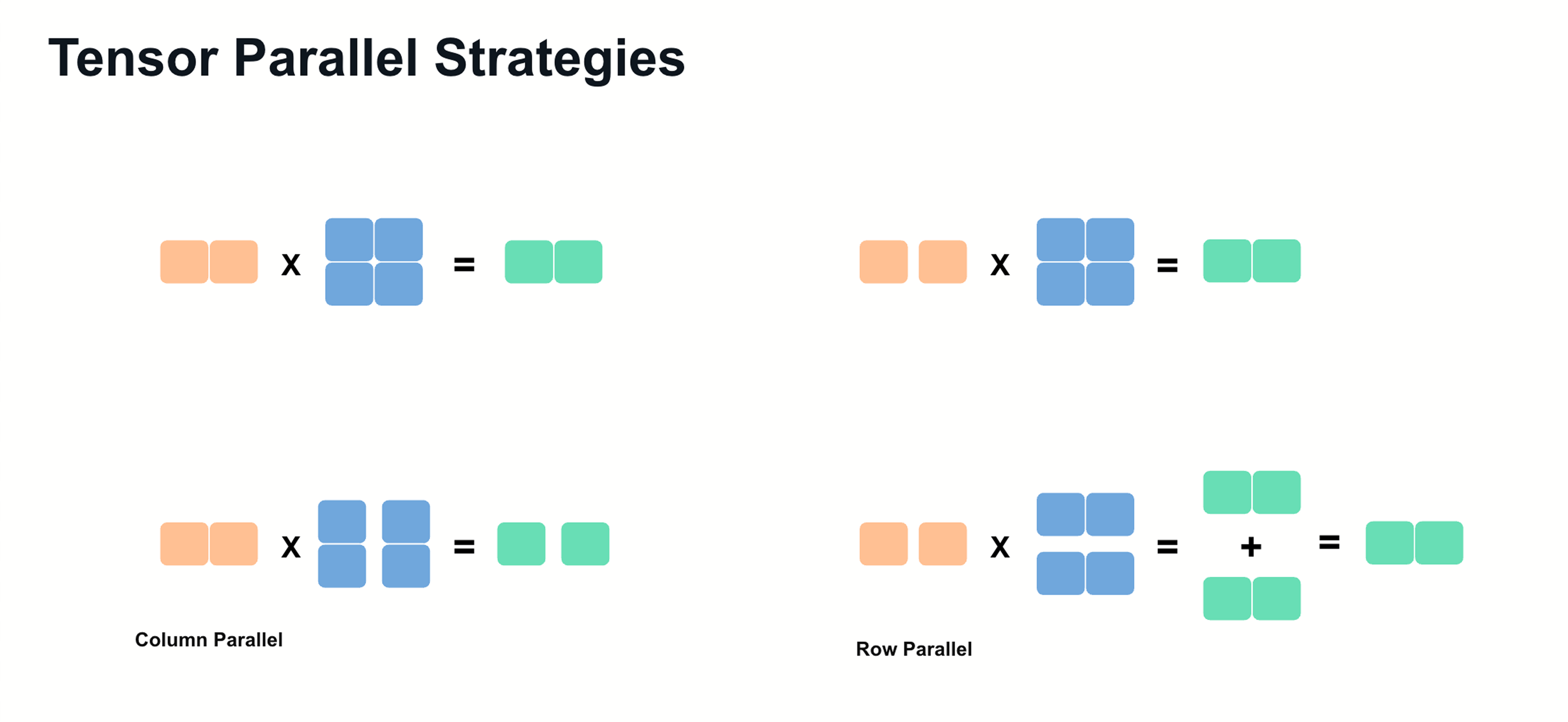
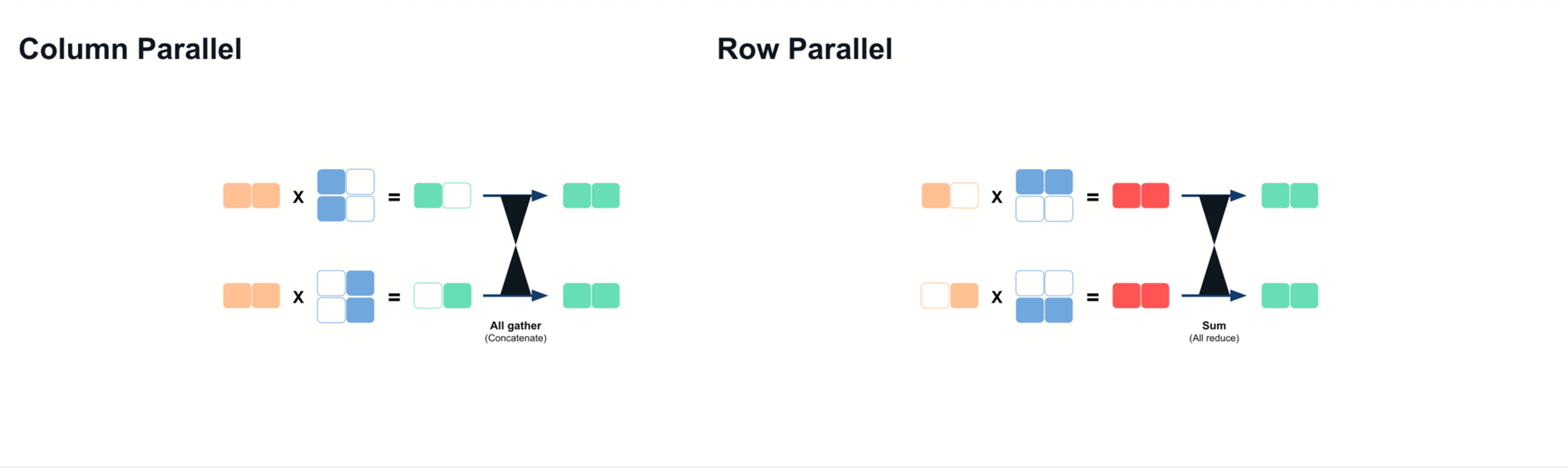
Sharding Large Models with Tensor Parallelism
tensor parallelism
Demystifying Tensor Parallelism | Robot Chinwag
Large Scale Transformer model training with Tensor Parallel (TP ...
Tensor Parallelism Overview — AWS Neuron Documentation
Tensor Parallelism — PyTorch Lightning 2.6.1 documentation
Tensor Parallelism in Transformers — How to Scale Transformer Models ...
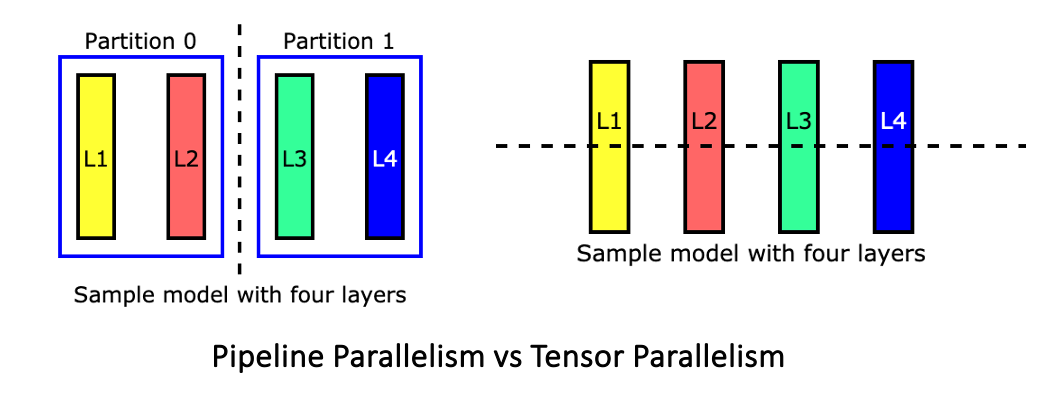
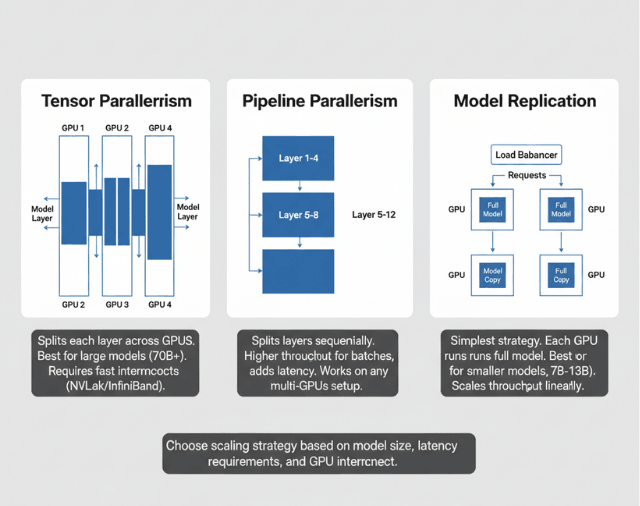
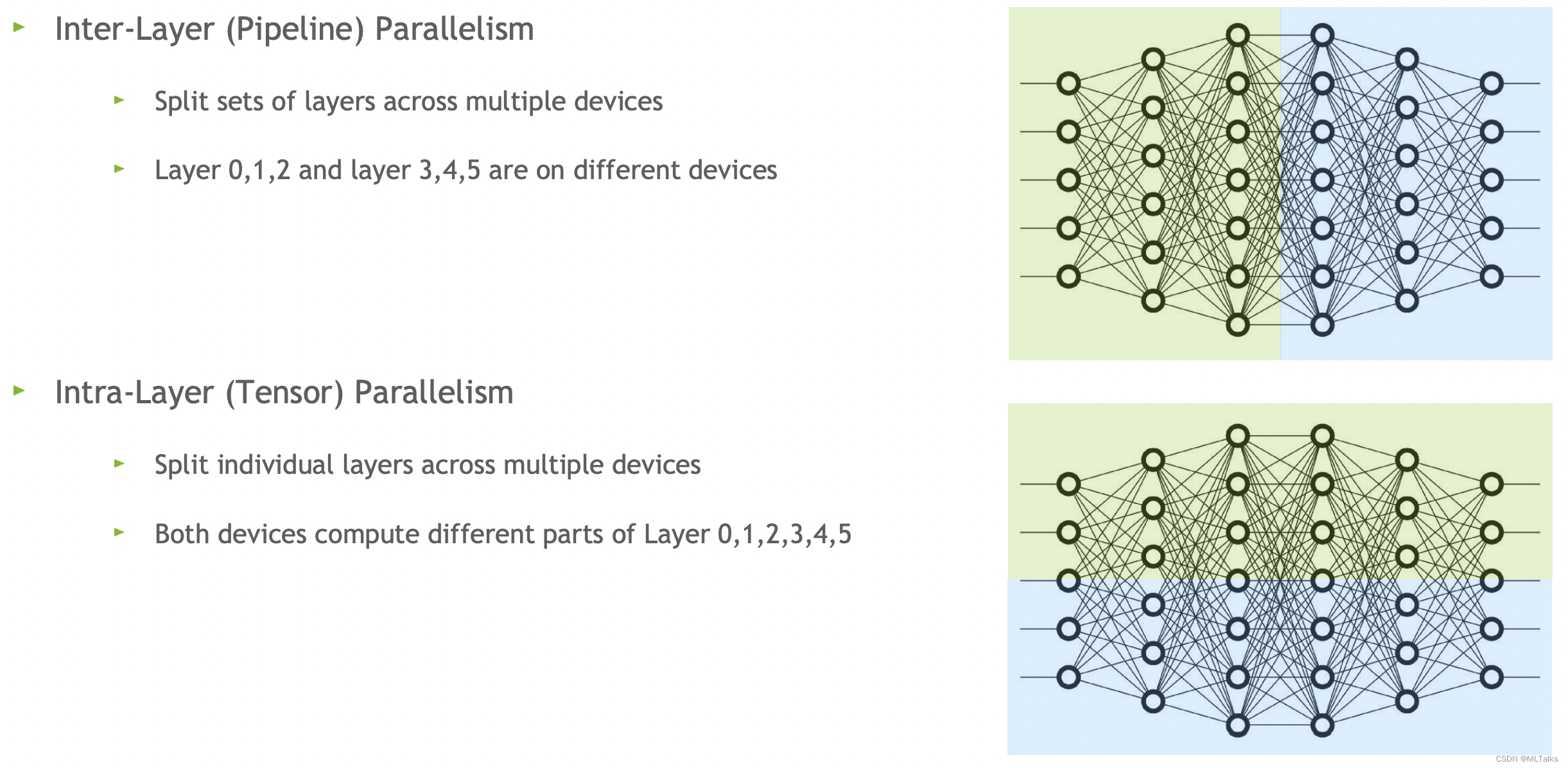
Model Parallelism Implementation (Tensor, Pipeline)
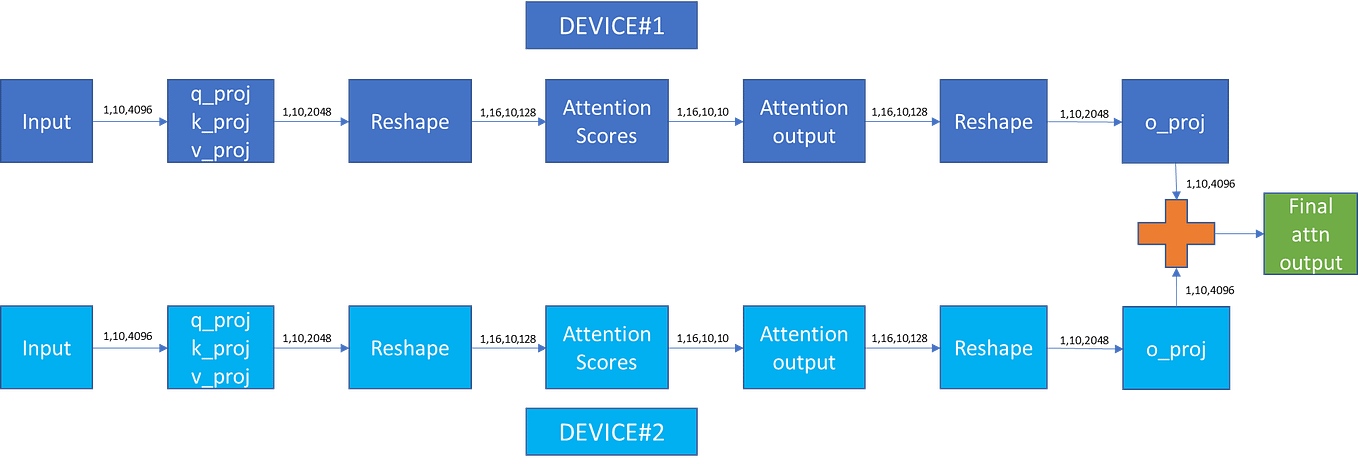
Tensor Parallelism in Transformers: A Hands-On Guide for Multi-GPU ...
Tensor Parallelism Explained
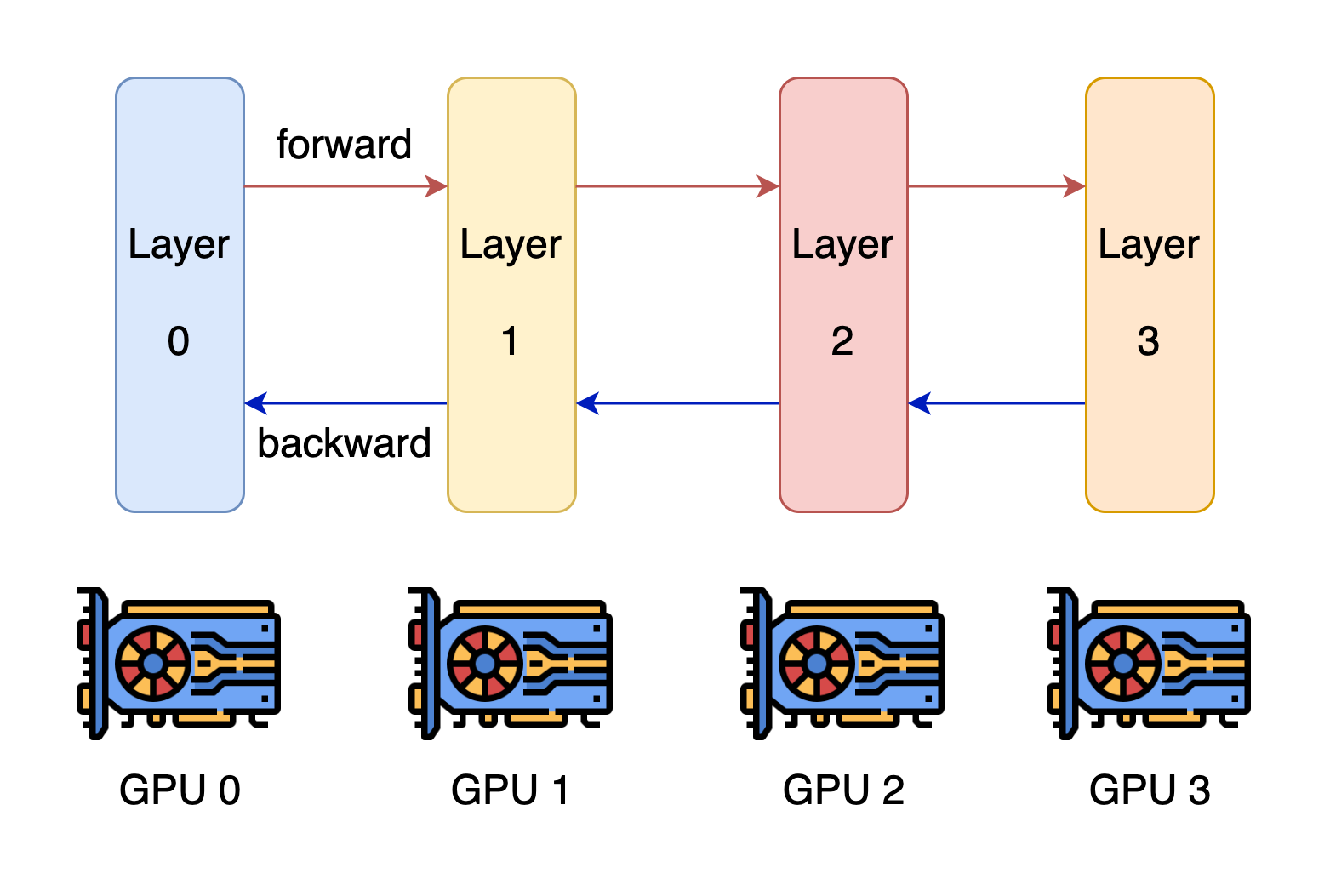
Tensor Parallelism and Pipeline Parallelism - Kyle’s Tech Blog
Scaling State-Space Models on Multiple GPUs with Tensor Parallelism ...
Tensor Parallelism and Sequence Parallelism: Detailed Analysis · Better ...
The Illustrated Tensor Parallelism | AI Bytes
Understanding Tensor Model and Optimizer Parallel Training | Course Hero
Data Parallelism vs Model Parallelism in AI Training
Tensor Parallelism | Ayar Labs
Perception Model Training for Autonomous Vehicles with Tensor ...
Pytorch2 Tensor Parallelism | Sharlayan
The Mechanics of Tensor Parallelism: A Deep Dive into Intra-Layer Model ...
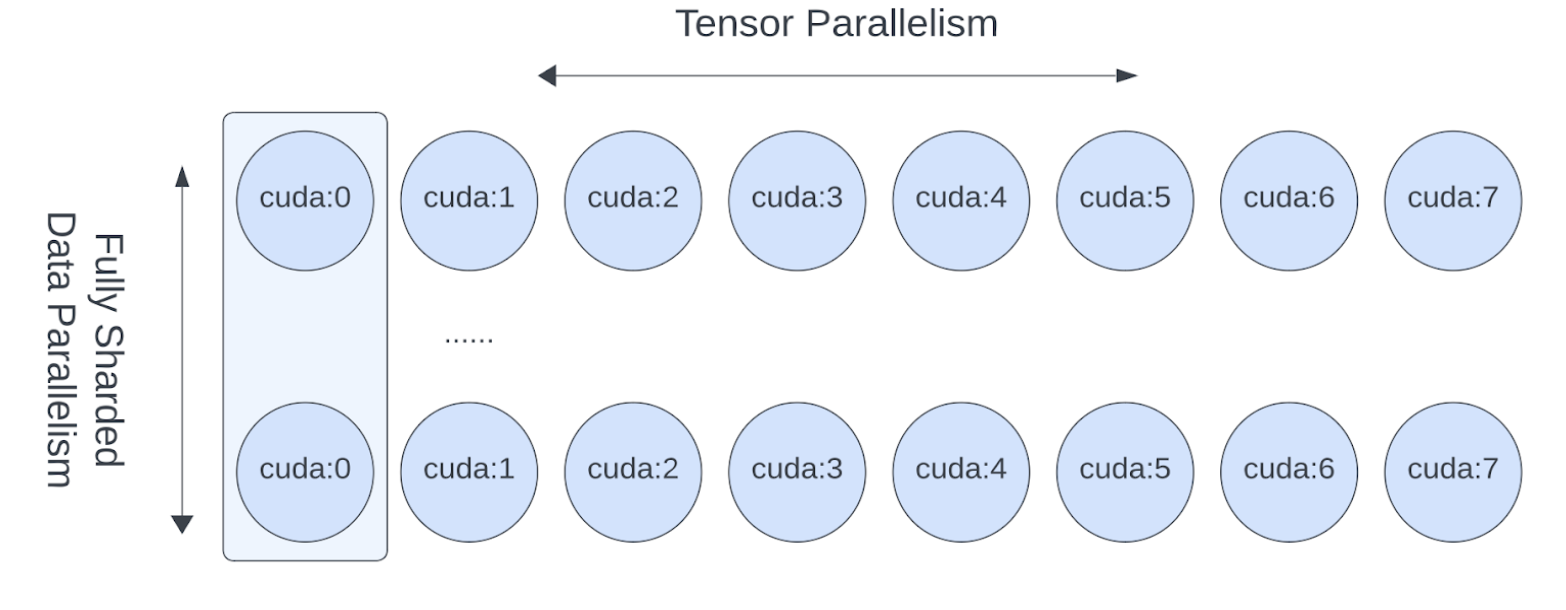
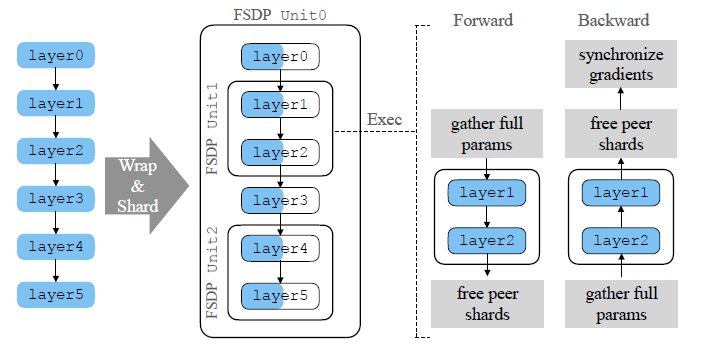
Tensor and Fully Sharded Data Parallelism
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
Tensor Parallelism (TP) in Transformers: 5 Minutes to Understand
Tensor Parallelism | sgl-project/mini-sglang | DeepWiki
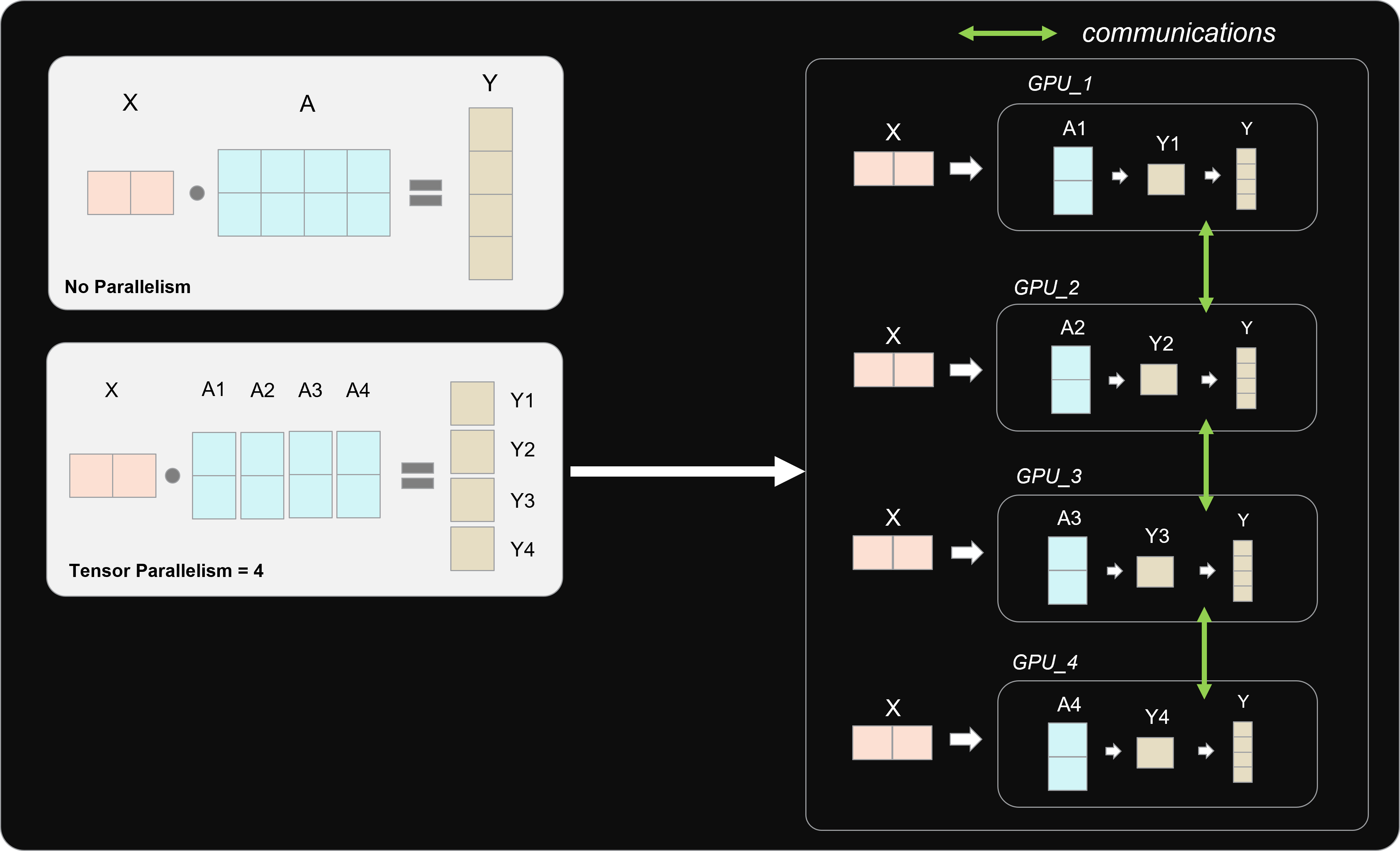
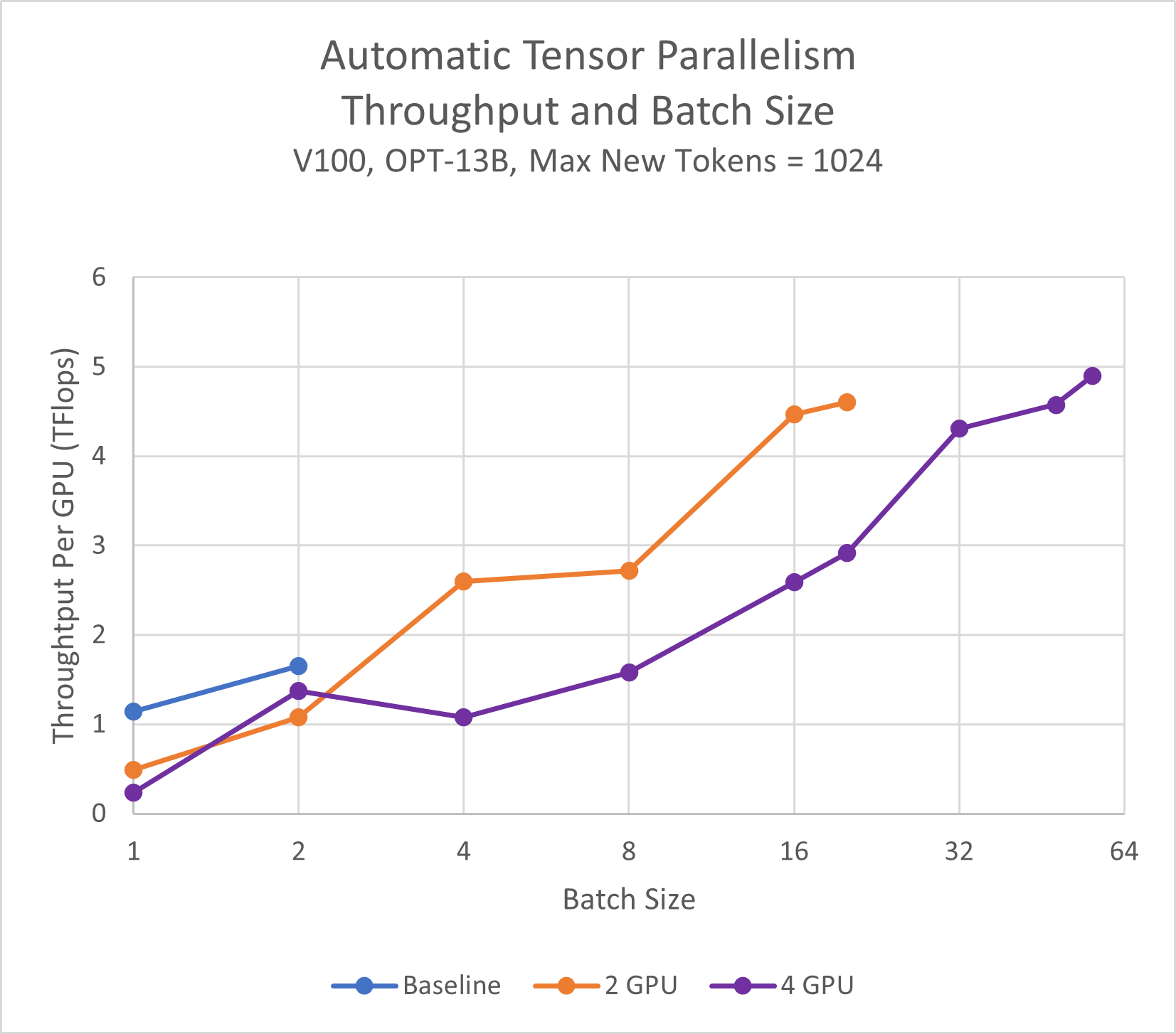
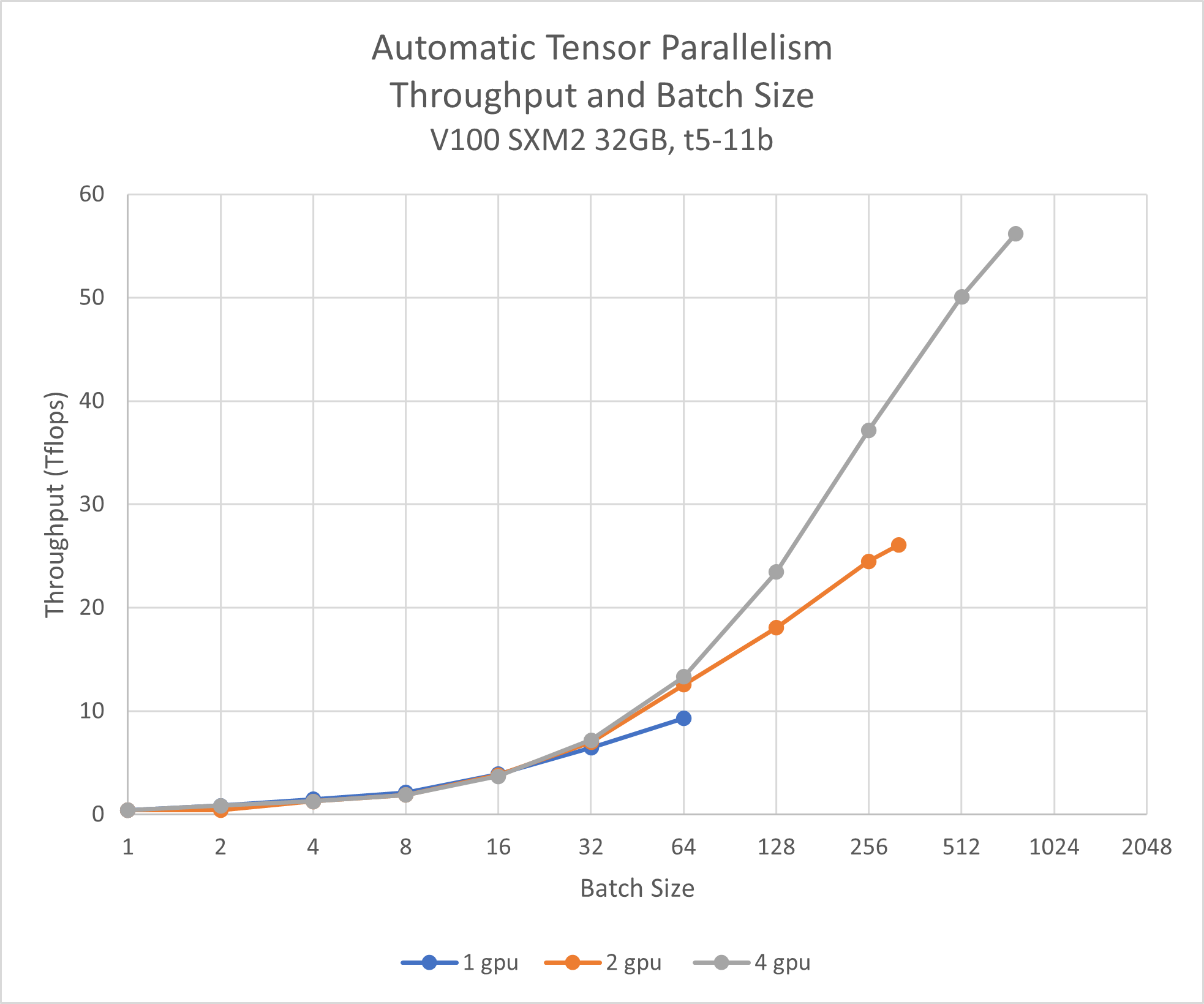
Automatic Tensor Parallelism for HuggingFace Models - DeepSpeed
Understanding tensor parallelism to fit larger models on multiple ...
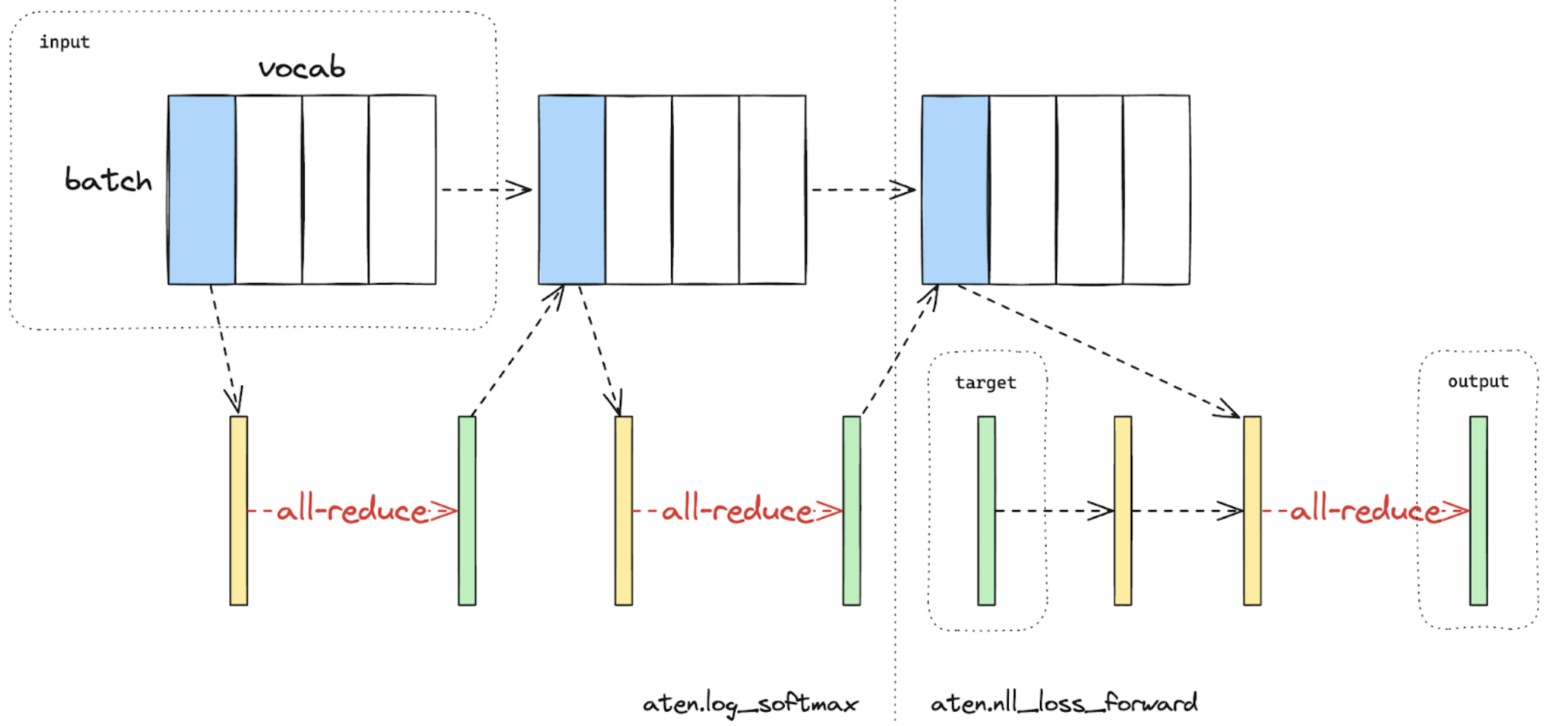
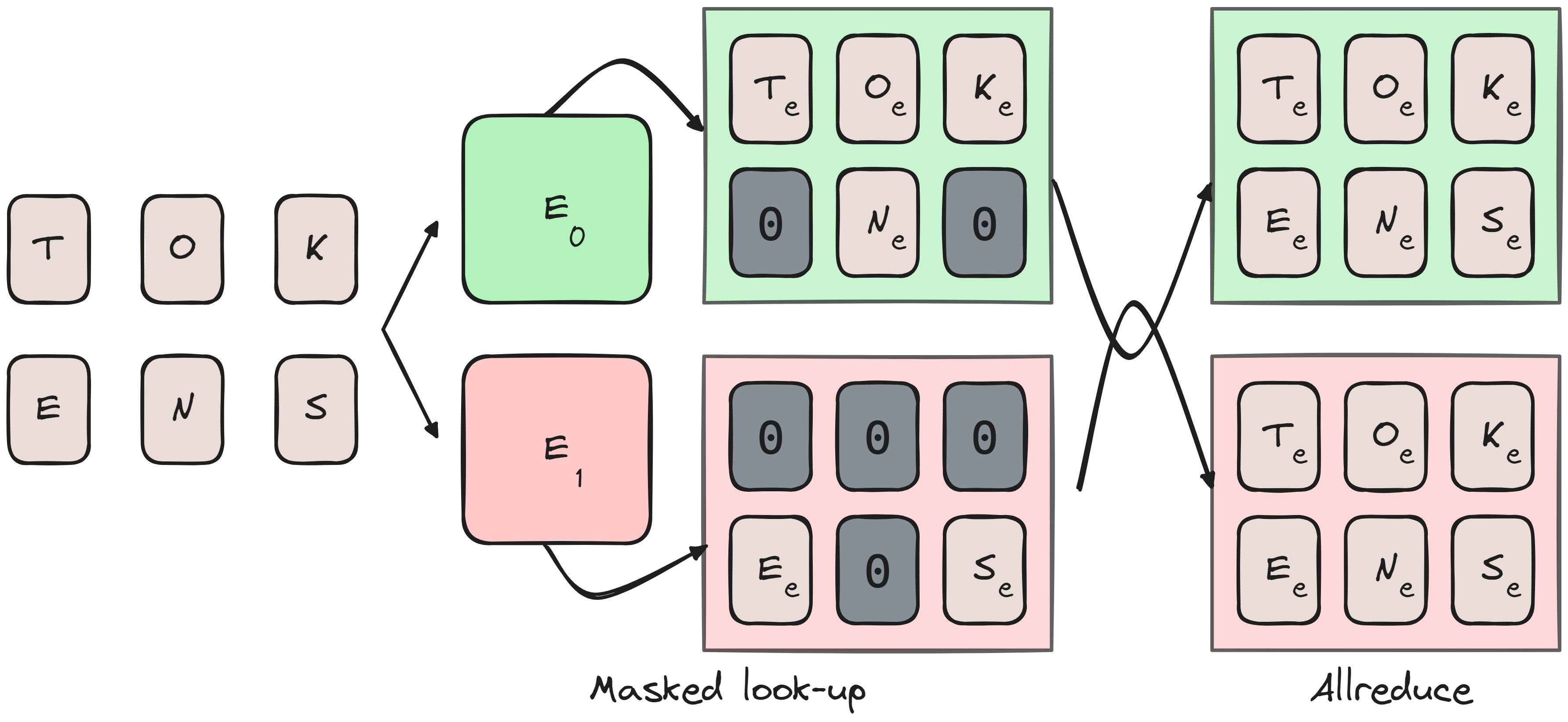
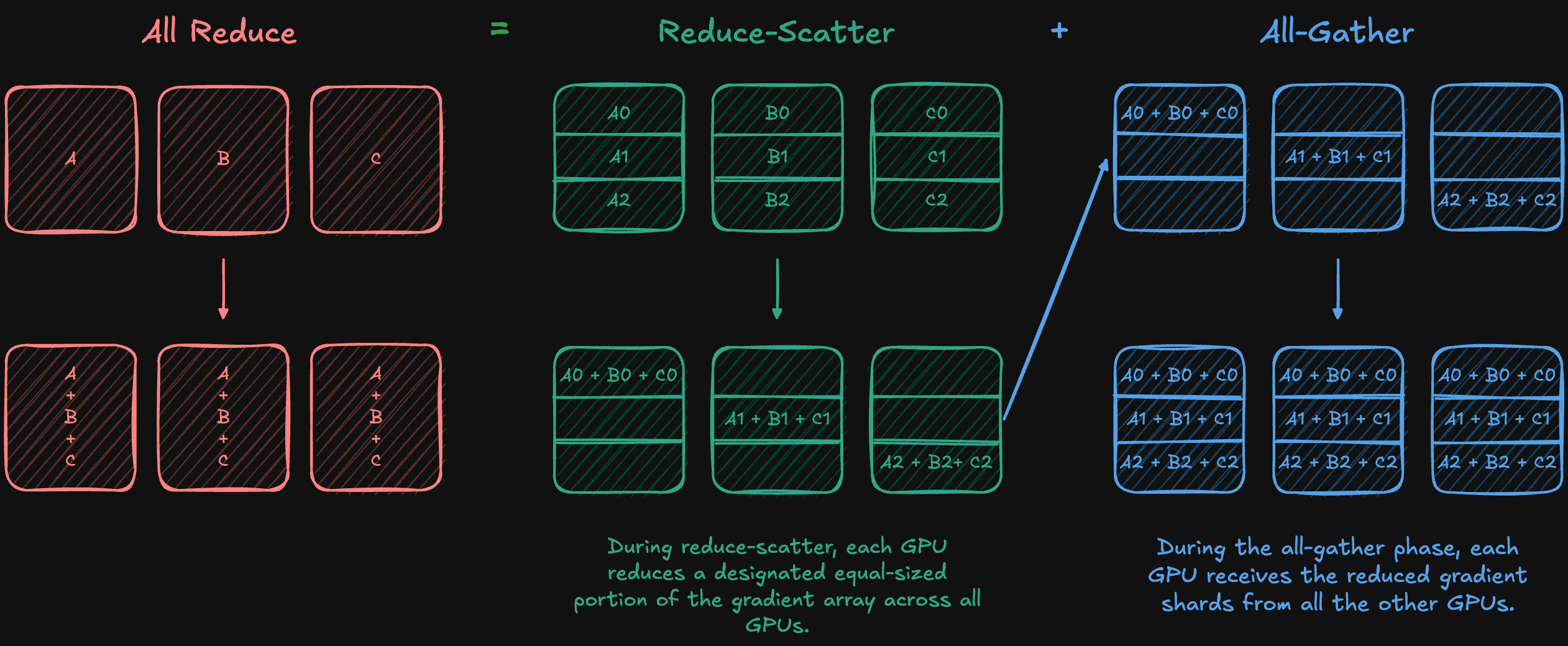
Ultrascale Playbook - Tensor and Sequence Parallelism | Blog
LLM Training — Fundamentals of Tensor Parallelism | by Don Moon | Byte ...
Model Parallelism
Efficient two-dimensional tensor parallelism for super-large AI models ...
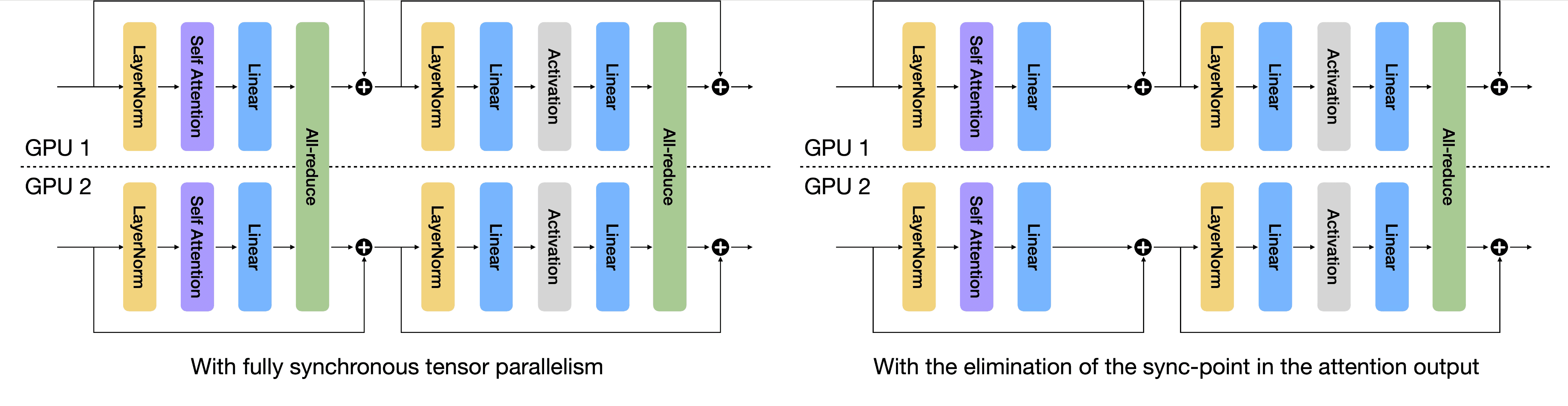
SPD: Sync-Point Drop for Efficient Tensor Parallelism of Large Language ...
一图说明tensor and pipeline model parallelism_1f1b pipeline.-CSDN博客
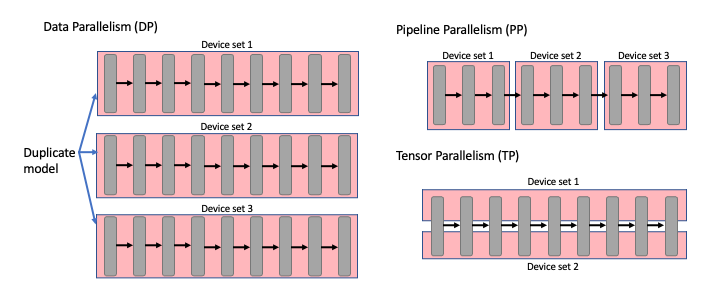
Data, Model, Tensor, and Pipeline Parallelism | SPC Blog
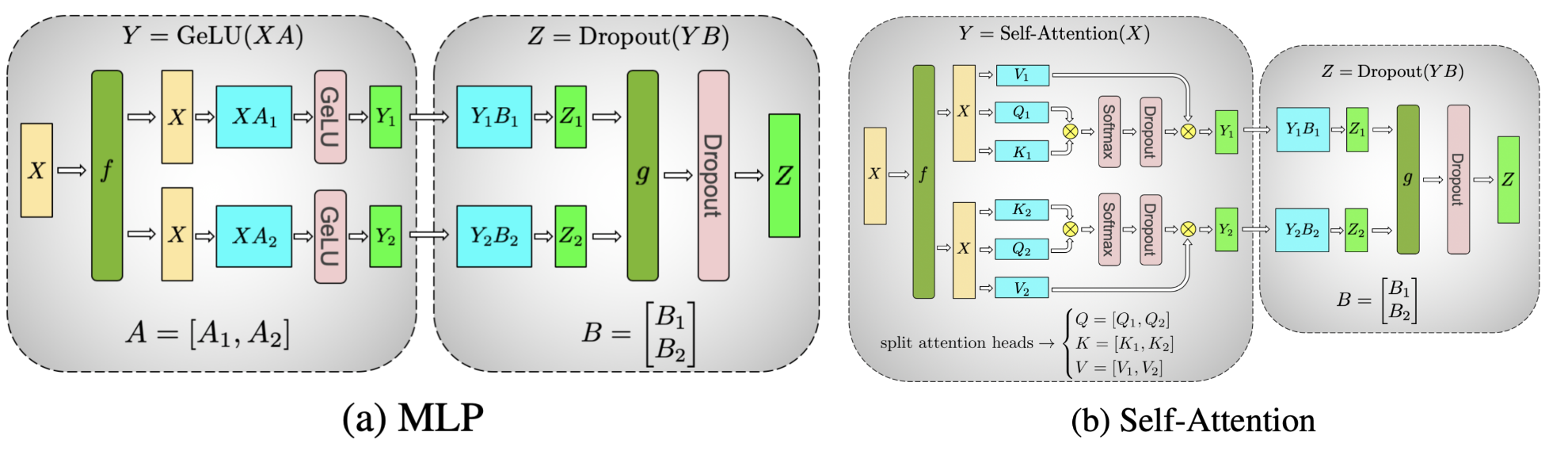
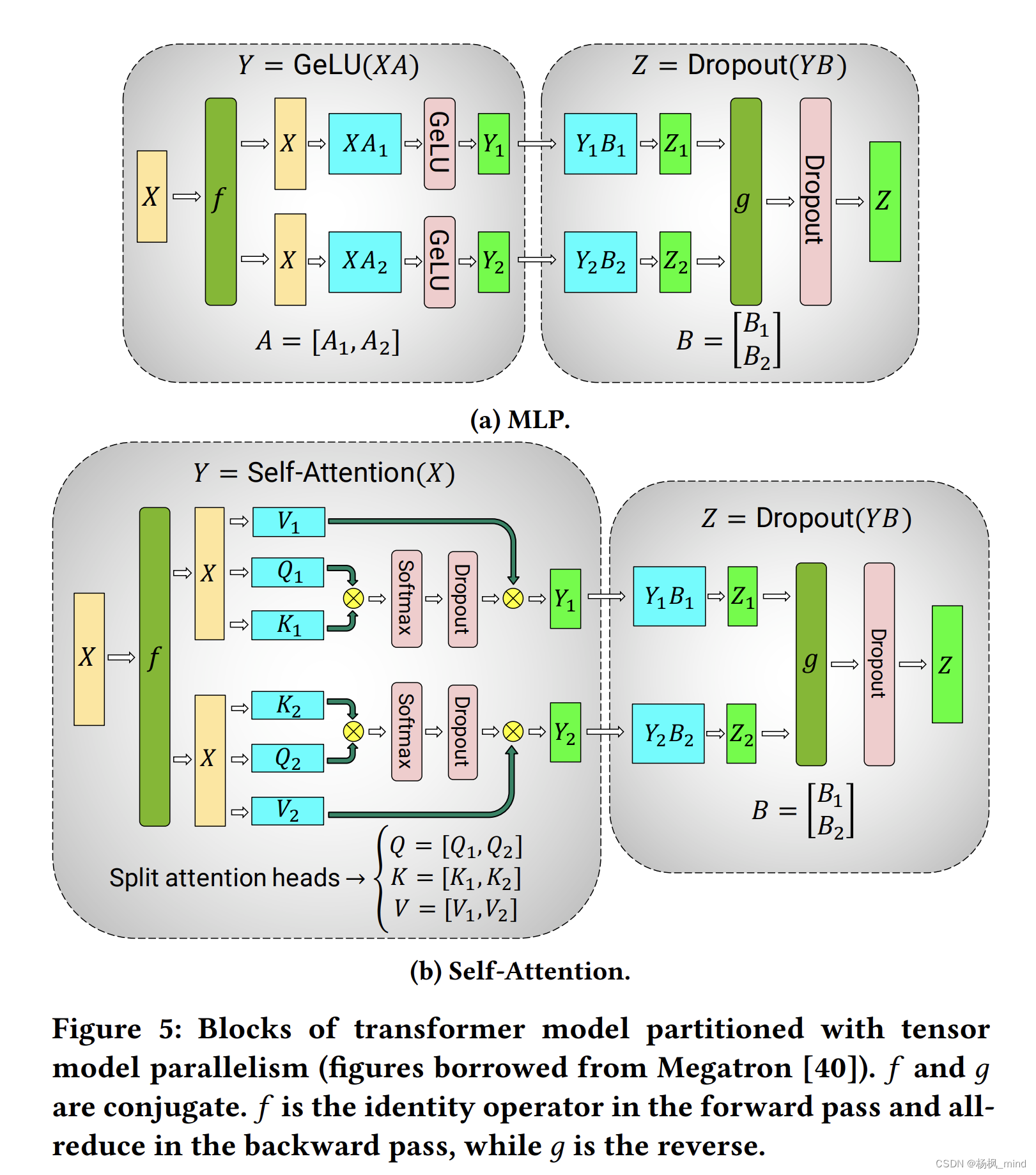
Scaling Language Model Training to a Trillion Parameters Using Megatron ...
How to Parallelize a Transformer for Training | How To Scale Your Model
Parallelism and Memory Optimization Techniques for Training Large ...
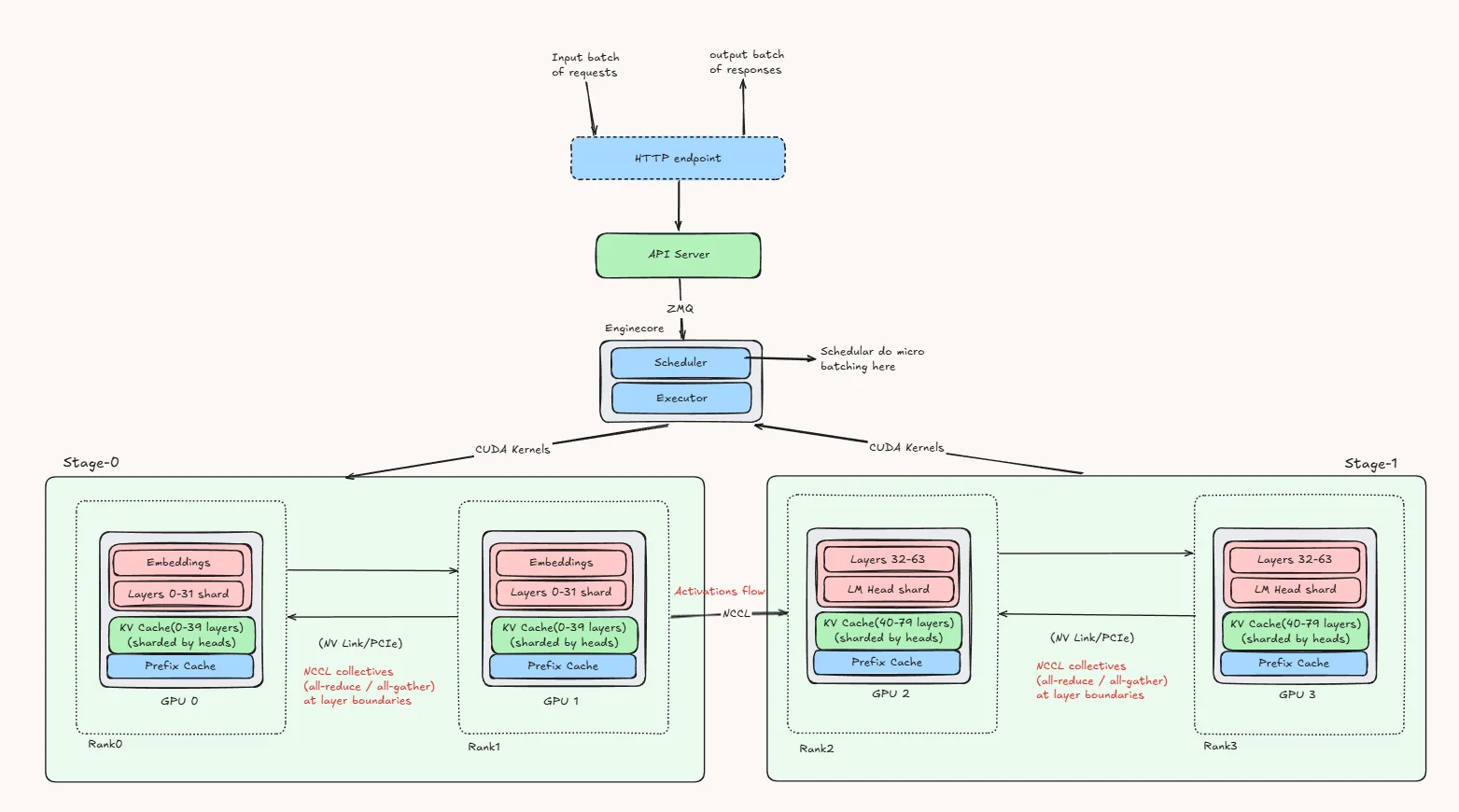
[vLLM vs TensorRT-LLM] #9. Parallelism Strategies - The official ...
Ranking Mechanism when Using a Combination of Pipeline Parallelism and ...
Running Large PyTorch Models on Multiple GPUs with Tensor Parallel fxis.ai
Train 175+ billion parameter NLP models with model parallel additions ...
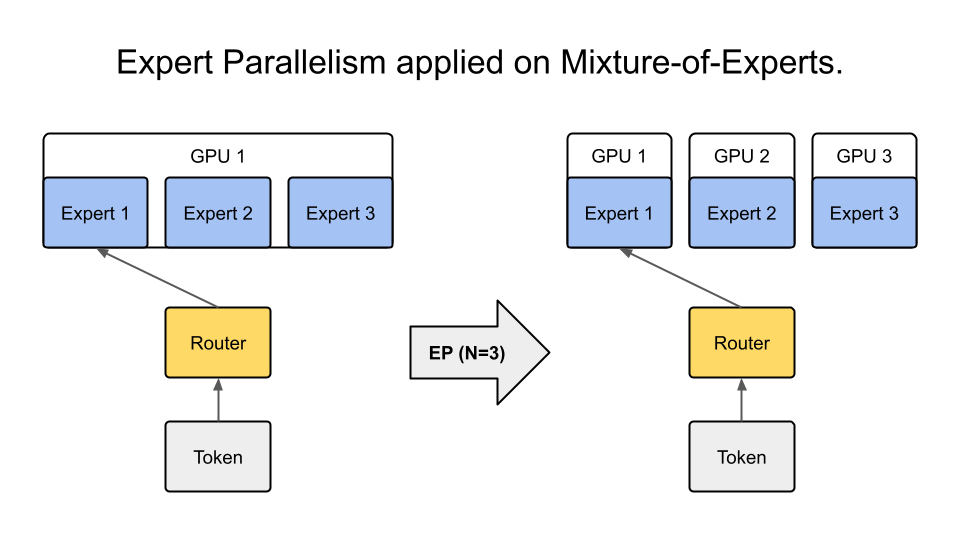
Expert Parallelism and Mixed Parallelism Strategies in vLLM | Jarvis ...
Global Tensor - OneFlow
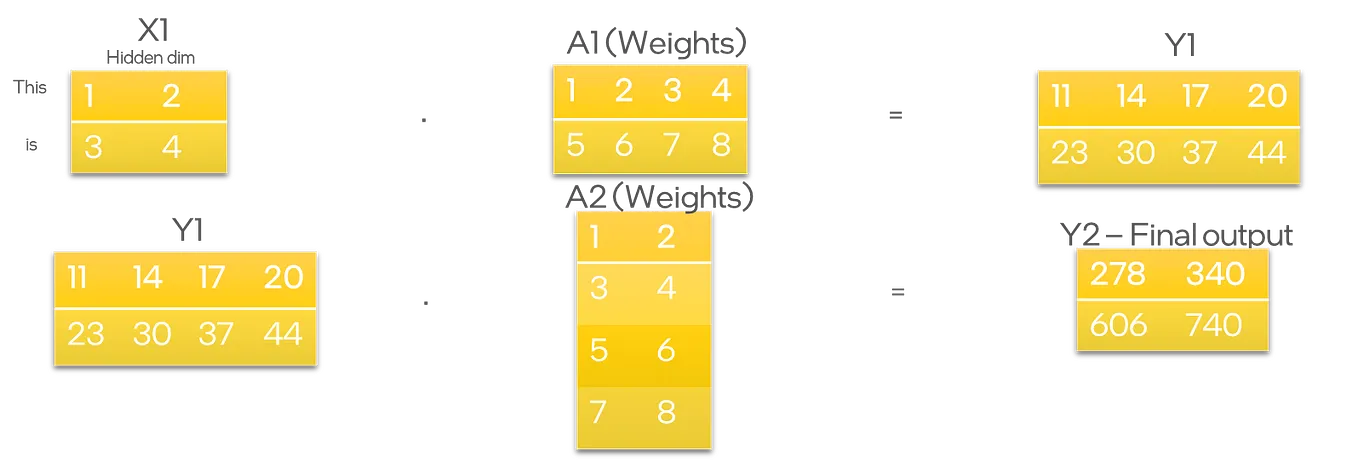
Illustration of tensor parallel. A merged version of Figure 2 and ...
NeMo2 Parallelism - BioNeMo Framework
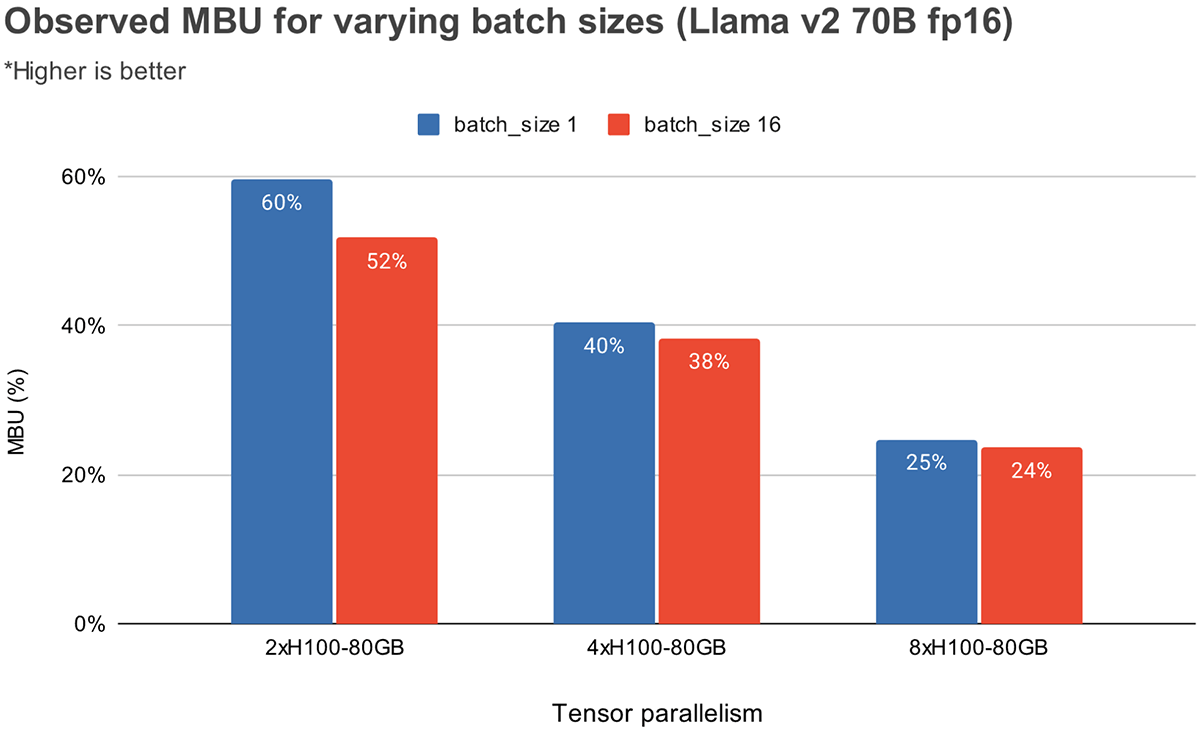
Appendix | Maximizing Llama Open Source Model Inference Performance ...
Paradigms of Parallelism | Colossal-AI
🚀 Beyond Data Parallelism: A Beginner-Friendly Tour of Model, Pipeline ...
LLM Inference on multiple GPUs with 🤗 Accelerate | by Geronimo | Medium
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
How to Optimize ML Models Serving in Production - Open Data Science ...
Distributed inference with vLLM | Red Hat Developer
Simplifying AI Inference in Production with NVIDIA Triton | NVIDIA ...
Parallelisms Guide — Megatron Bridge
Demystifying AI Inference Deployments for Trillion Parameter Large ...
PyTorch Distributed Data Parallel (DDP) Training in Kaggle
Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM ...
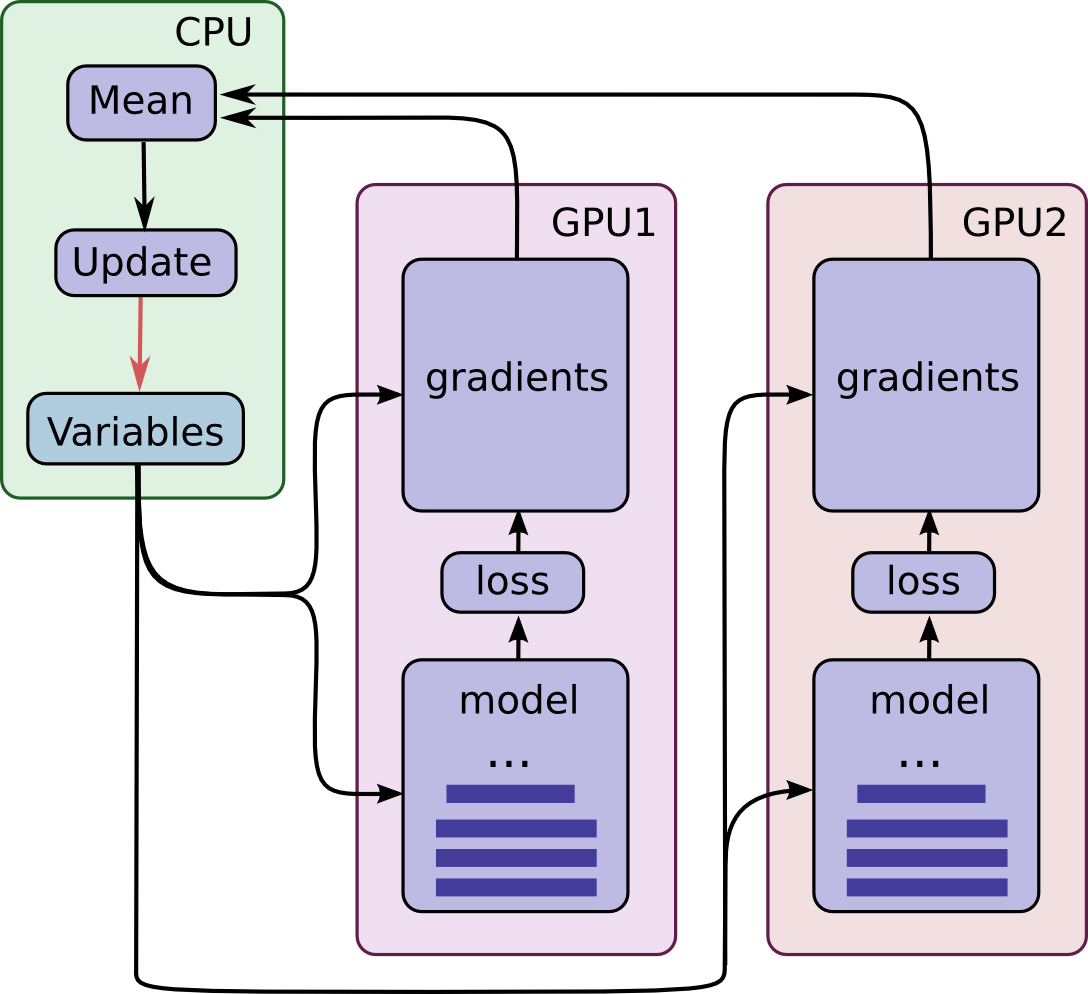
Train a Neural Network on multi-GPU · TensorFlow Examples (aymericdamien)
NVIDIA, Stanford & Microsoft Propose Efficient Trillion-Parameter ...
Efficient Training on Multiple GPUs
How to Train Really Large Models on Many GPUs? | Lil'Log
GitHub - BlackSamorez/tensor_parallel: Automatically split your PyTorch ...
Data, tensor, pipeline, expert and hybrid parallelisms | LLM Inference ...
Optimizing Memory Usage for Training LLMs and Vision Transformers in ...
Reducing Activation Recomputation in Large Transformer Models | DeepAI
GPU Guide for LLM Deployment - RTX 4090 to A100 Benchmarks (2026)
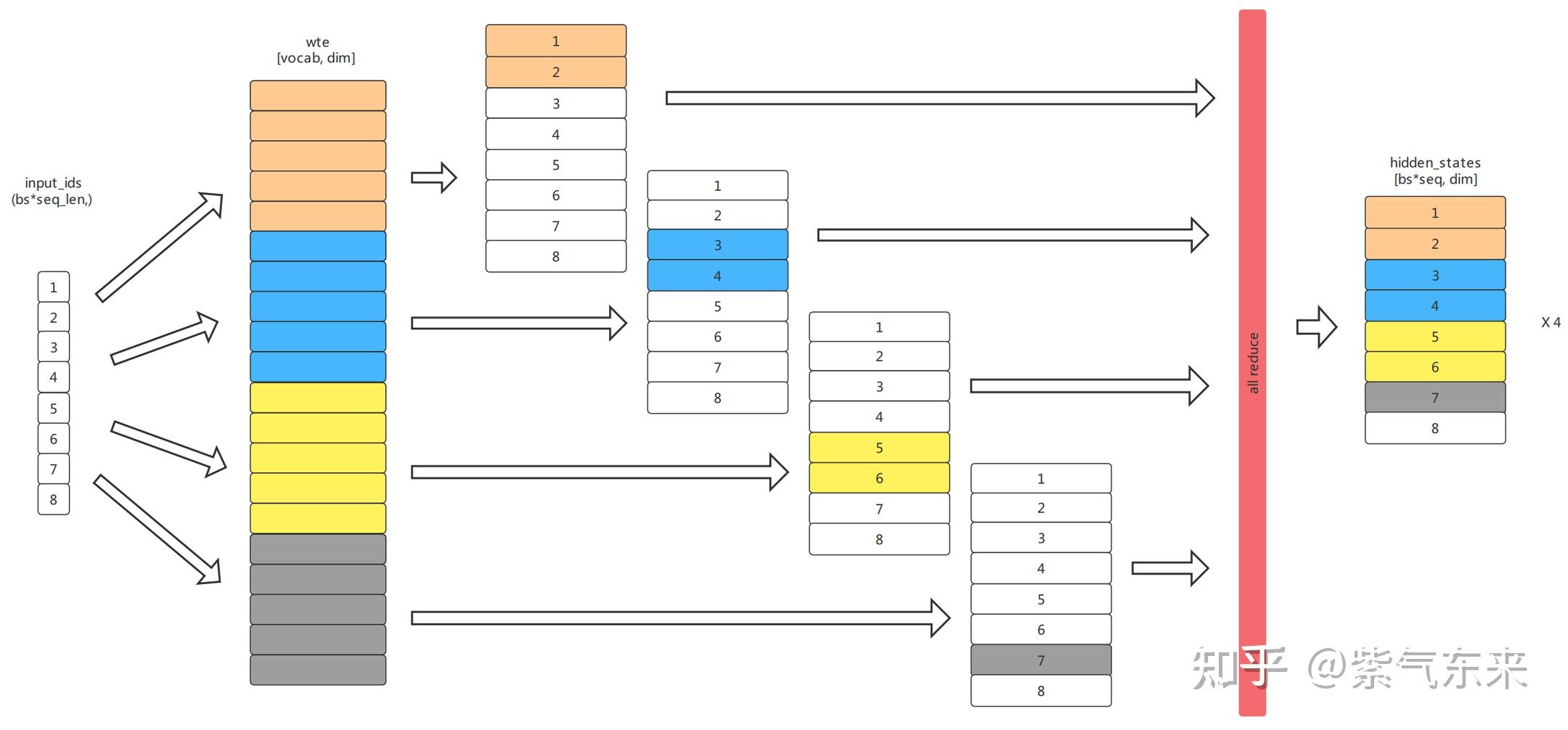
LLM(六):GPT 的张量并行化(tensor parallelism)方案 - 知乎
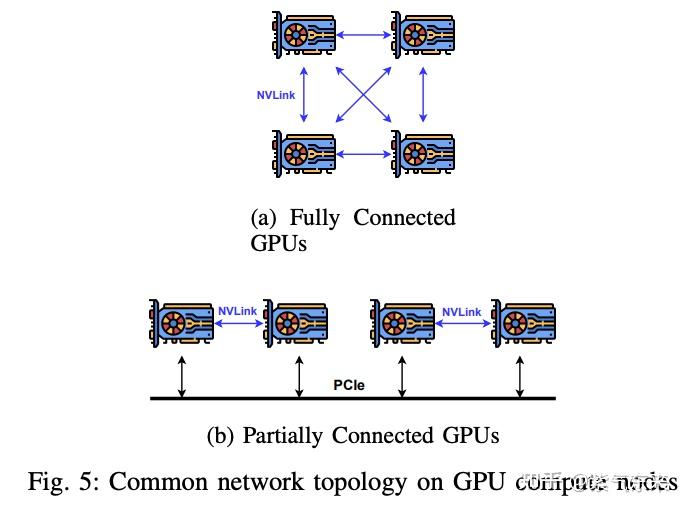
Evolution of Distributed Training in Deep Neural Networks | Lazy Loaded ...
Chapter 07 | Sebastian Raschka, PhD
Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled ...
详解MegatronLM Tensor模型并行训练(Tensor Parallel)_megatron-lm-CSDN博客
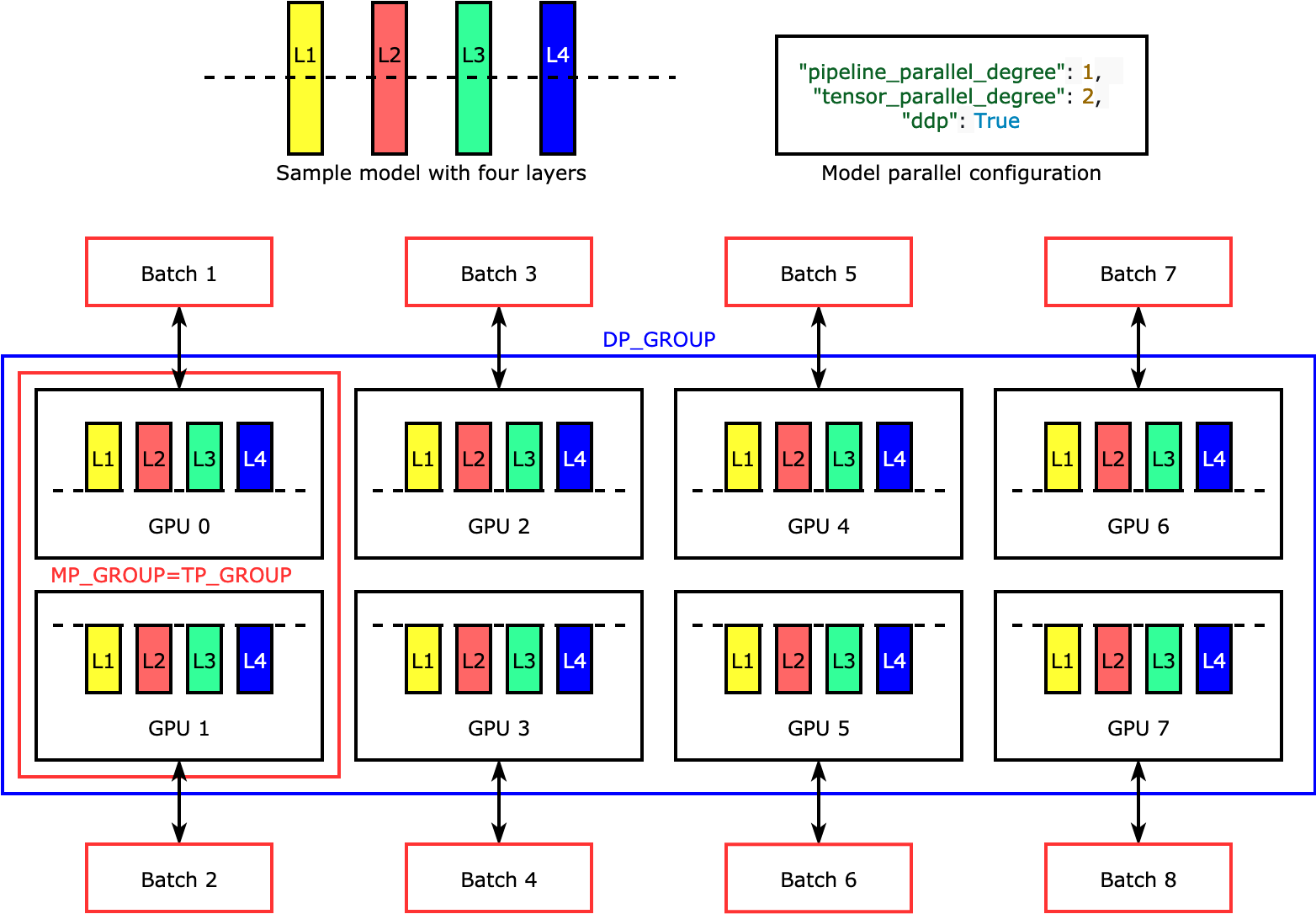
Example distributed training configuration with 3D parallelism, with 2 ...
LLM(6):GPT 的张量并行化(tensor parallelism)方案 - 知乎
來自 OpenAI gpt-oss 的技巧,您🫵可以在 transformers 中使用 - Hugging Face 文件
LLM Inference Performance Engineering: Best Practices | Databricks Blog